I’ve got a teammate and friend at Ginkgo, Ray, and I’m sorry to say his condition is, well, it’s not good.
…
Get it? Get it?! “Ray’s condition, not good” — or rather, “Race condition, not good”?! Well, fine. I’m a software engineer, not a comedian. (To be clear, Ray has nothing to do with this story aside from having a convenient name for the purposes of this post. Also, I believe he’s in good health.)
I thought I’d share a little bit about a bug I encountered in our software recently. This turned out to be a race condition, hence that whole opening bit you’ve already suffered through. I’d seen race conditions in college, way back when, and in a theoretical sense, but this was my first time running into one in the wild.
First, some background. This was on a software portal website that we simply call “Portal.” It is a React app paired with Apollo.
We’ve got quite a few applications here at Ginkgo. I was working on a feature to ensure that users who log into Portal are properly set up in some of our other Ginkgo apps.
Portal was already making a query GET_CURRENT_USER in a component CurrentUser shortly after user login. Great! I figured I could bootstrap onto GET_CURRENT_USER: in addition to resolving everything we already had, our backend for GET_CURRENT_USER would query those other Ginkgo apps to check if the user’s account was properly set up there, and then return that information to the frontend, which could proceed accordingly. One tradeoff here is that the new GET_CURRENT_USER would take a little longer to resolve. However, this seemed like a one-time hit because Apollo caches its results, so we wouldn’t have to query again the next time we needed the data.
The Bug
That was my implementation. It looked good in code review and testing, then … uh-oh! Two completely different, unrelated pages within Portal, both owned by another team, broke. By “broke”, I mean that we started getting that big old React “White Screen of Death”, with an indication, “TypeError: Cannot read property ‘currentUser’ of undefined”. Well, that sure seems related to the changes I made.
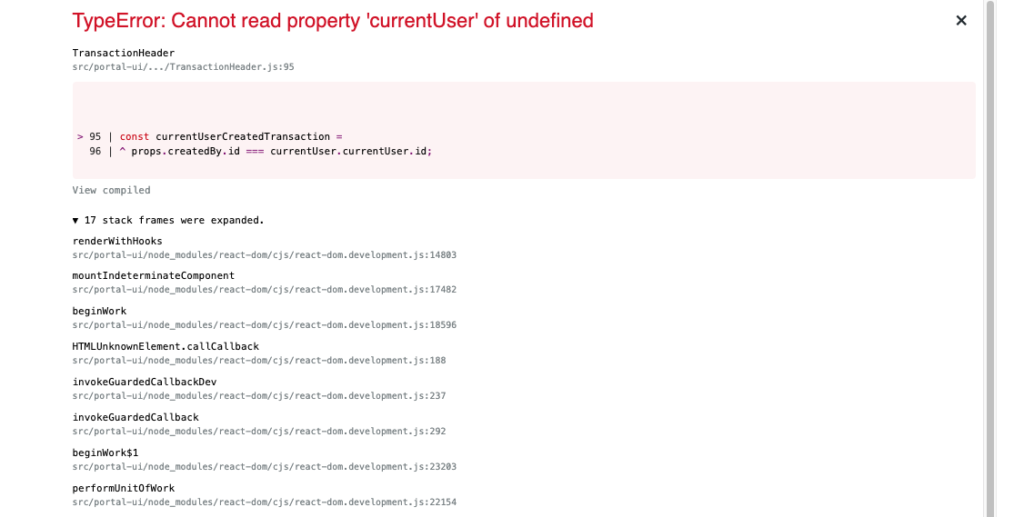
Time to put on my debugging hat. The React components that broke were called TransactionHeader and SequenceViewer. Both of these components made their own call to GET_CURRENT_USER, on the Transaction page and Design Unit page respectively. And since my commit changed GET_CURRENT_USER, that seemed to cinch it that these errors were my fault. But why? Sure, GET_CURRENT_USER was taking longer to resolve, but that shouldn’t have mattered. There were three things that had me surprised and skeptical:
- (1) Handling this sort of async data return is one of the things that React+Apollo is pretty good at as compared to the wild west web development days of 15 years ago.
- (2) We use static type checkers like Flow to warn us of these issues in advance.
- (3) Most importantly, weren’t the results of GET_CURRENT_USER in the cache? CurrentUser is loaded immediately upon login to Portal, whereas TransactionHeader and SequenceViewer both take some navigating to get to. So shouldn’t CurrentUser’s call populate the cache well before we reach the pages that feature TransactionHeader and SequenceViewer? And if that’s the case, then my changes to GET_CURRENT_USER should be immaterial.
I sat down and recreated the user experience here, and quickly realized the answer to (3). The pages featuring TransactionHeader and SequenceViewer both open in completely new browser tabs — which means we have to kick off the whole React render tree from the top down. Uh-oh! The cache benefits I was so excited about, which offset the increased load time that my commit introduced, largely disappear as a result of this, since there’s no more navigating to these pages from within the React app.
Once (3) disappears, (1) and (2), which are admittedly rather handwavy, seem like much less of a sure thing.
After a tiny bit of digging, there was an obvious problem I could see in TransactionHeader and SequenceViewer: we made a query which returned a currentUser object, and then we had logic that relied on a property in that object, without actually checking to see if the query had returned yet and if the object was fully resolved. This is a very common mistake; I’ve made it myself plenty of times.
Digging Deeper in Lieu of a Quick Fix
An obvious fix, now that we’ve spotted this problem, is to make the logic in TransactionHeader and SequenceViewer more cautious. We will be implementing that change, but I was curious if I could constrain myself to a solution that didn’t touch those two components. What was puzzling was _why now_. What was it about my change that triggered this TypeError issue? For that matter, how were these components fully operative up until this point?
I downloaded a nifty Chrome extension, URL Throttler, to help me debug here. (Yes, Chrome Developer Tools allow you to institute throttling on your network requests, but not on a per-URL basis, which is what I needed in this case.) Sure enough, if I throttled the response time for the endpoint that GET_CURRENT_USER was hitting, even the version of GET_CURRENT_USER that preceded any of my commits, I could trigger the bug.
At this point, I ceased my analysis. I hadn’t remotely gotten to the root cause of the issue yet, but I figured, “Okay, for some reason or another, it’s important that GET_CURRENT_USER not take too long to resolve. That’s why the code’s been working up until now — we’ve been getting lucky — our query had been returning fast enough that we never ran into this lurking issue. (There’s our race condition, by the way.) How about I change my original commit so that CurrentUser calls its own special query, GET_CURRENT_USER_WITH_EXTERNAL_ACCOUNTS, and the other components can continue making use of the original GET_CURRENT_USER. That should basically restore the status quo, and with any luck, we might still get lucky with the cache here.”
I implemented this — everything seemed to be working! The Design Unit page, which featured SequenceViewer, now loaded without a hitch, even if I throttled the endpoints that GET_CURRENT_USER_WITH_EXTERNAL_ACCOUNTS and GET_CURRENT_USER were hitting.
I thought that was the end of it. And yes, perhaps you realized immediately what I somehow overlooked: “what about the Transaction page, and TransactionHeader”? As a software developer, it’s important to be methodical, but I’d neglected to test this case until the very end. (A savvier marketer than me might instead say, “I had carefully thought out a test plan that involved checking the Transaction page only after I’d thoroughly tested the Design Unit page and SequenceViewer”!) In any event, whether my hapless testing scheme was intentional or inadvertent, I was still out of luck: for some reason, my fix didn’t work on TransactionHeader.
Deeper Still…
Now I was really confused. Didn’t my workaround effectively restore the status quo as far as TransactionHeader was concerned? How on earth did I manage to address the issue on one page but not the other? I was definitely going to have to investigate more and get at the root cause of these issues if I was to have any hope of devising a fix.
Having a sense of what was in Apollo’s cache, and when, might have been illuminating. This was possible for me to accomplish (I must commend Apollo on how thorough their documentation is), but non-trivial. I hoped to find another way to understand what was going on.
It was about now that I stumbled upon one of the tabs in Chrome Developer Tools that I’d previously always glanced over, the Performance tab. Before this point, I’d been using the Network tab to get a sense of which query was getting fired off when. This was effective enough, but hardly a proper profiling solution.
Once I analyzed the page load via the Performance tab, I could see what was happening more clearly.
Approaching the Problem Systematically
There were a few different cases I wanted to understand:
- Case (A), the status quo, where all the components employ GET_CURRENT_USER — the lurking race condition which yields the TypeError exists but never manifests itself.
- Case (B), my original commit, which makes GET_CURRENT_USER take longer to return — the TypeError consistently gets triggered.
- Case (C), my workaround with both GET_CURRENT_USER_WITH_EXTERNAL_ACCOUNTS and GET_CURRENT_USER — bizarrely, this consistently resolves the issue on the Design Unit page but just as consistently produces a TypeError on the Transaction page.
The profiler helped me definitively answer my questions about cases (A) and (B). I could see that CurrentUser was higher up in React’s render tree. CurrentUser would launch GET_CURRENT_USER, which, in case (A), returned before we even started to render TransactionHeader or SequenceViewer. Therefore, the necessary data was (“were”, for my pedant friends out there) in the cache already: TransactionHeader and SequenceViewer wouldn’t even make their own queries, and no TypeError.

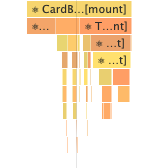
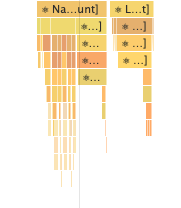
In Case (B), CurrentUser’s GET_CURRENT_USER would not return in a timely fashion. React would proceed down its render tree, eventually rendering TransactionHeader or SequenceViewer depending on which page we were on. These components will not make their own GET_CURRENT_USER calls because Apollo knows that there’s a call for this particular resource already on the wire. Meanwhile, React will continue loading the remainder of those pages. Boom, TypeError!
The big question was whether Case (C) would show different things for the Design Unit page (i.e. SequenceViewer) than the Transaction page (i.e. TransactionHeader).
Let’s start with the Transaction page. CurrentUser launched GET_CURRENT_USER_WITH_EXTERNAL_ACCOUNTS. Meanwhile, React rendered everything else, eventually getting to TransactionHeader. I could see that a new request GET_CURRENT_USER was being emitted, this time from TransactionHeader. Then, since React continued loading the remainder of the page before either query returned, the app would crash on a TypeError.
In the Design Unit page, CurrentUser launched GET_CURRENT_USER_WITH_EXTERNAL_ACCOUNTS. React proceeded along, eventually getting to SequenceViewer, and — huh? No GET_CURRENT_USER call emitted by SequenceViewer? Why not?! I could see it in the code, right there! TransactionHeader produced a GET_CURRENT_USER call but SequenceViewer did not — this smelled fishy, and called for further investigation.
The Revelation, or, A Killer Unmasked
I had Case (A) and Case (B) in hand. We’ll skip over a good hour or so of confused bumbling as I tried to understand what was happening in Case (C). (To say nothing of all the previous bumbling I’ve elided over from this tidy account… but hey, that’s what learning looks like!)
Eventually, I decided to take a step back, and get more of a bird’s-eye view. I discovered that higher up the render tree, SequenceViewer had an ancestor component called DesignUnitProfile — which made _its own_ call to GET_CURRENT_USER. Moreover, DesignUnitProfile was set up such that by the time SequenceViewer rendered, DesignUnitProfile’s GET_CURRENT_USER would probably have returned (though it wasn’t a sure thing either … a separate race condition, arguably).
That was it! SequenceViewer didn’t run into the TypeError in Case (C) because, like in Case (A), it had a cached currentUser object it could consult before the error-triggering condition was evaluated. In contrast, TransactionHeader had no such cached object because of its different render tree. If we hadn’t gotten lucky (unlucky?) with that additional call to GET_CURRENT_USER that was already in DesignUnitProfile, my workaround fix would have produced the same behavior on both the Design Unit page and the Transaction page — which is to say, still a consistent TypeError, and no fix at all.
In narrating this whole experience, perhaps I should have mentioned or foreshadowed DesignUnitProfile earlier, given that it turned out to be important. DesignUnitProfile is the accomplice in a murder mystery who you don’t even know exists until everything is revealed, so the revelation of his (its) involvement, upon which the plot hinges, hardly matters to you anyway.
But because I didn’t find out about DesignUnitProfile myself until the very end, I wanted you to have the same experience. I even knew from the beginning that GET_CURRENT_USER showed up in more components than the error-causing two I mentioned at the beginning, but since the stack traces directed me to TransactionHeader and SequenceViewer, that was where I focused my attention, and yours.
Well, just imagine having spent several hours digging into this, and perhaps you can relate to how indignant I felt when I finally got the full picture of what was going on.
With this understanding in hand, we ended up implementing a fix, the details of which are beyond the scope of this post, but which allow CurrentUser to continue using a timely-returning GET_CURRENT_USER so that the query results maintain their advantageous early-loading into the cache.
Some Takeaways
What did I learn from all of this? Here’s a non-exhaustive list of some thoughts:
- The “Performance” tab on Chrome Developer Tools — a wealth of information!
- Race conditions are subtle. This one wasn’t even so bad in that I eventually found a way to reliably reproduce the problem. I feel proud for eventually having gotten to the bottom of it.
- Remember my offhand comment, “having a sense of what was in Apollo’s cache, and when, might have been illuminating”? In hindsight, this was spot-on, especially for Case (C). However, the cost-benefit tradeoff of making this happen was probably substantial … my bad luck.
- Regarding my analysis of Case (C): having a detailed view of things was essential, but ultimately not revealing. Zooming out (literally: enlarging the time interval I was looking at in the profiler) led to the required clarity and complete understanding.
- When I first started investigating all of this, I had a handful of open tabs covering some of the different cases, and a rough sense of what I wanted to look into. Pretty quickly, though, I was swimming in too many details to keep track of in my head. Writing down my findings, even provisional ones, even just offhand ideas, helped me get my thoughts in order and come up with a more systematic way to tackle the problem.
Thanks for joining me on this rather specific walkthrough! We certainly got in the weeds, as one is wont to do when tracking down bugs, but hopefully you’ve also come away with some of the same general takeaways with which I emerged.
(Get it? “E-merged”? As in, “merged in new commits, electronically”? No, it doesn’t really work, does it. I was afraid not. Well, lightning doesn’t strike twice.)
(Feature photo by Jonathan Chng on Unsplash)
