The Strategy
Sometimes, you need to send an update to multiple independent systems. One strategy is to use a distributed transaction. Unfortunately, distributed transactions are some of the most dangerous beasties in software architecture. Among the risks: tight coupling of otherwise remote systems, combinatorial explosion of dependencies, and blocking due to unavailable servers.
Alternatively, you may be able to use an event streaming strategy. One of Ginkgo’s recent projects used this strategy to great benefit.
This is a two part post. In Part 1, I’ll explain the project, show how and why we used an event streaming strategy, and list some pros and cons. In Part 2, I’ll provide some practical tips that helped us implement the strategy.
What is Event Streaming?
“Event streaming” is a very broad term, so permit me to explain what I mean. Here, it means a strategy of publishing events to event streams.
An event is a message that describes a business occurrence that has already happened. An event is not a request (something that can fail to happen), and events are immutable (they can never change or “unhappen”).
Event streams are ordered, persisted, and append-only. In other words, a distributed log or ledger. Event streams are shared across your ecosystem; in principle, any consumer can opt-in to consume events of interest to them.
Practically speaking, events form a collaborative, shared, business-domain language across your software ecosystem. This is a powerful design tool and requires commensurate levels of care. With great power comes great responsibility.
The Project
One of our COVID testing labs uses automated lab machinery and robotics controlled by industrial-grade control software (a SCADA stack, specifically Ignition). This lab is super awesome and we’ll talk more about it some other time. But for now, let’s just say that this high-volume system performs a lot of biological operations. For example, a (very simplified) event might say “liquid handler W added X microliters of reagent Y to every well in 96-well plate Z.”
Many different consumers must be informed of these operations. For example:
- Our Laboratory Information Management System (LIMS) tracks the location, status and lineage of biological samples and labware.
- Other lab operators must be informed so they can perform related work, such as loading the lab outputs into our sequencers.
- Scientists review measurements to perform biological validation (specificity and sensitivity targets).
- These workflows are subject to CLIA regulation, so our compliance team verifies and reports on our compliance.
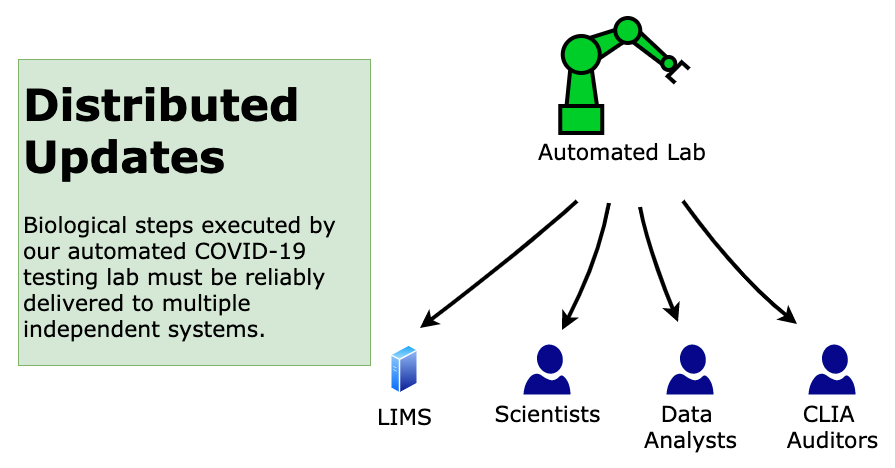
A distributed transaction strategy would block the lab until after every possible consumer has acknowledged the update, so it would not work here. We instead stream the updates as events that are eventually consumed by the downstream systems.
The Architecture
Our architecture looks like this:
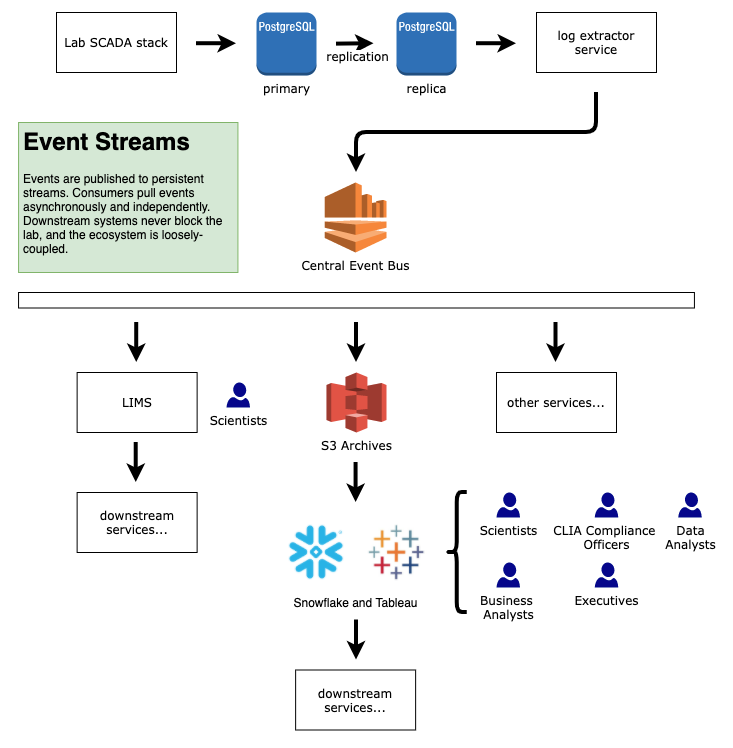
- The SCADA system writes records to its on-prem database.
- The on-prem DB is replicated to a replica DB, so that big queries can’t adversely impact the primary DB.
- A log extractor service polls the replica DB for new records and constructs events. The extractor is both a translation gateway and event publisher.
- The log extractor service pushes the events onto a central event bus (CEB) implemented in AWS Kinesis (Kafka would also be a great choice).
- Various event consumers subscribe to the CEB, and pull at whatever rate they desire.
- The CEB is also configured to copy all events to an AWS S3 bucket for long-term archiving (i.e. cold storage) or post-hoc analysis.
- Our data warehouse (in Snowflake), loads events from S3 and analyzes it. Among other outputs, we provide views in Tableau.
Pros and Cons
The Pros
Most importantly, downstream outages never block the lab. More generally, local outages are contained and do not cause cascading failures.
The consuming systems remain decoupled. The various parts can continue to evolve without hidden dependencies. It is also trivial to add more event consumers in the future.
Teams are also decoupled. This lab system, and the software supporting it, was built by seven teams all working at the same time. Events are a less tightly-coupled form of communication than service APIs. Teams spent less time blocking each other, speeding up overall development.
The system is fault tolerant and eventually consistent. Assuming the SCADA system can make the initial write to its local database, all systems will eventually converge to a consistent state and no data is lost. We didn’t need to use any strategies like 2PC or consensus algorithms.
Event archives are useful for “post-hoc” analysis. If you’ve ever had to kludge a CDC (AKA changelog, AKA change table) into your running database, you’ll appreciate having an event history you can use instead.
The collaborative nature provides a social mechanism to detect and correct misunderstandings across teams, including non-dev teams. A real-world example: our data analytics team, who would typically not be in API design meetings, was involved in our event design. They caught countless design errors, preventing costly rework. To paraphrase Eric S. Raymond: “Given enough eyeballs, all design errors are shallow.”
The Cons
The most common challenge with event streaming is “I’ve never done event streaming before and am not sure how to do it.” Take heart! The problems may be unfamiliar, but they are usually solvable. I’ll provide some practical advice in Part 2.
You’ll probably write more code. Events will supplement, but not replace, APIs. Some things are unavoidably transactional and should not be expressed as events. Therefore you’ll still need classical service APIs. Trying to stuff a transactional update into an event is the number one mistake you need to watch for. I’ll talk more about that in Part 2.
Designing the event schemas can be challenging if you’ve never done it before. What should and shouldn’t be an event? What level of detail should the event have? How much additional context should I add? What level of granularity should events have?
Eventual consistency always brings its own challenges. While they are usually solvable, you need to spend time up-front thinking about them. For example, most services should have an SLA for “max lag time” (duration between an event being published and the service consuming it).
You’ll have to think about how consumers work when in “catch up mode.” If a service has, for any reason, fallen behind, it may need extra capacity to catch up. It may want to warn users about stale data, raise alerts, and or log more (or less) information to the app logs. Your monitoring metrics should track event backlogs.
You may need new infrastructure and security models to support a shared bus. Note: DO use a stream broker like Kinesis or Kafka. Do NOT use a queue broker like RabbitMQ or SQS. An event stream is a persisted, append-only, distributed log, not a queue of ephemeral messages.
Reflection
We built it, and it works! Of course, it’s great that we completed the project, but just as importantly, we gained practical experience with event streaming. This is a new tool in our toolbox, and we already see opportunities to use it in future work.
That wraps it up for Part 1. In Part 2, I’ll present some guidelines that we found useful during implementation.
(Feature photo by Ryan Lara on Unsplash)
