Hey everyone, Dan here! I write software at Ginkgo Bioworks and am the creator of the vaccinetime Twitter bot which helps people find open COVID-19 vaccine appointments in Massachusetts. I wrote the vaccinetime bot after noticing how much time coworkers were spending trying to find a vaccine appointment, sitting on the registration page for hours looking for spots. I thought, rather than spending all that time manually looking, why not automate the process instead!
The basics of a bot like vaccinetime include a few different parts. The purpose of the bot is to look at vaccine appointment websites on a regular basis, detect any new appointments that have been posted, and tweet about them. To achieve this, it includes code that looks at websites and parses their information (called “scraping” a website), code for sending a Tweet automatically, and code to run both of these on a schedule so that it can detect changes quickly. All this is written in Ruby, although the following examples should be easy to understand with no previous Ruby experience.
Web Scraping
Web scraping is a bit of an art that involves a lot of detective work and puzzle solving. To solve this part I had to look under the hood of the vaccine appointments websites to try to understand their structure and how they worked, then program some code to read them. For this post, we’ll be looking at the maimmunizations.org website, which was the first site added to the bot. It lists appointments like this:
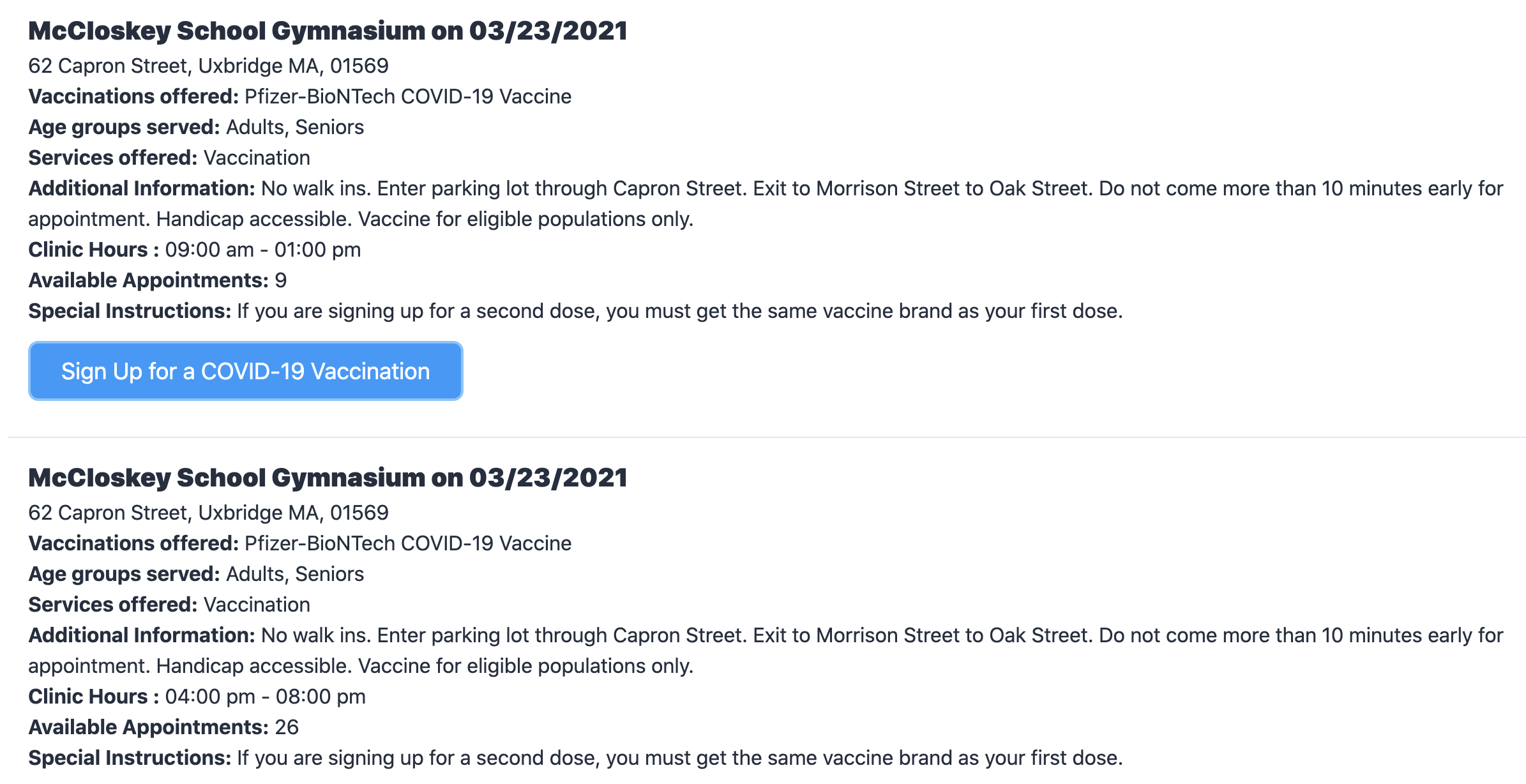
To understand the structure of the page, we can inspect the HTML in the browser’s developer console by right clicking and selecting “Inspect”:

HTML tags are the basic building blocks here and are delimited by angle brackets like <p>. For the maimmunization.org site, information for each clinic is contained in some <div> tags each with the class “justify-between”. Each one of these sections includes the name of a clinic, the date, and some <p> (paragraph) tags listing further information including the vaccine type, age groups served, and available appointments. To easily parse and work with this page data, vaccinetime uses the rest-client and nokogiri Ruby gems. rest-client is a simple HTTP and REST client for Ruby, and Nokogiri is an HTML parser. The code for parsing the structure of the page roughly works like this:
require 'rest-client'
require 'nokogiri'
response = RestClient.get('https://clinics.maimmunizations.org/clinic/search?location=&search_radius=All&q[venue_search_name_or_venue_name_i_cont]=&clinic_date_eq[year]=&clinic_date_eq[month]=&clinic_date_eq[day]=&q[vaccinations_name_i_cont]=&commit=Search')
html = Nokogiri::HTML(response.body)
sections = html.search('.justify-between')
sections.each do |section|
paragraphs = section.search('p')
next unless paragraphs.any?
title = paragraphs.first.content
clinic_information = {}
paragraphs.each do |p|
description, value = p.content.split(':')
next unless value
clinic_information[description.strip] = value.strip
end
appointments = clinic_information['Available Appointments']
end
Let’s break this down to understand each part. The first thing it does is make a web request to the site and initializes a Nokogiri object. Don’t worry about the long URL, that’s just what the maimmunizations.org site has for its search page:
response = RestClient.get('https://clinics.maimmunizations.org/clinic/search?location=&search_radius=All&q[venue_search_name_or_venue_name_i_cont]=&clinic_date_eq[year]=&clinic_date_eq[month]=&clinic_date_eq[day]=&q[vaccinations_name_i_cont]=&commit=Search')
html = Nokogiri::HTML(response.body)
After that the HTML is broken into sections using the “justify-between” class we saw above. Nokogiri provides a search function that will search for any matching HTML within an existing tag and we can search for a particular class by prepending the search text with “.”:
sections = html.search('.justify-between')
The code then iterates over each section using Ruby’s each function, which is like a for loop in other languages:
sections.each do |section|
For each section it looks for <p> tags using the Nokogiri search function again and skips the section if there are none:
paragraphs = section.search('p')
next unless paragraphs.any?
It finds the clinic’s title in the first paragraph tag by accessing the content function:
title = paragraphs.first.content
Handling the other paragraphs requires more careful processing because each section may have a different number of paragraph tags within it containing various information. Instead of relying on appointments being in a particular spot, vaccinetime looks over each paragraph using each and creates a hash called clinic_information. A Ruby hash is a way of storing key/value pairs, so it’s a perfect fit for this use case where we want to associate the description of a paragraph (e.g. “Available Appointments”) with its value (9). The split function is used here to split each paragraph’s text using the “:” symbol as a delimiter between the description and value. It skips any paragraph that may not have a delimiter, and finally the strip function is used to strip off any extra whitespace that may be in the values:
clinic_information = {}
paragraphs.each do |p|
description, value = p.content.split(':')
next unless value
clinic_information[description.strip] = value.strip
end
This makes it really simple to look up the appointment information, like this:
appointments = clinic_information['Available Appointments']
Tweeting as a Bot
Let’s move on to see how vaccinetime can send out a tweet once it finds something, using the twitter gem. For this it uses a custom Ruby class:
require 'twitter'
class TwitterClient
def initialize
@twitter = Twitter::REST::Client.new do |config|
config.consumer_key = ENV['TWITTER_CONSUMER_KEY']
config.consumer_secret = ENV['TWITTER_CONSUMER_SECRET']
config.access_token = ENV['TWITTER_ACCESS_TOKEN']
config.access_token_secret = ENV['TWITTER_ACCESS_TOKEN_SECRET']
end
end
def tweet(text)
@twitter.update(text)
end
end
The TwitterClient reads some environment variables to log in to Twitter as the bot, and then provides a tweet function that sends a tweet. The TWITTER_ variables are provided by Twitter when creating a bot here: https://developer.twitter.com/en/docs/twitter-api, and the bot uses them like a password to log in to Twitter. The client is used in code like this:
twitter = TwitterClient.new
twitter.tweet("Hello World!")
Tying It All Together
Together the code is used to check a site and tweet when appointments are available like this:
require 'rest-client'
require 'nokogiri'
require 'twitter'
class TwitterClient
def initialize
@twitter = Twitter::REST::Client.new do |config|
config.consumer_key = ENV['TWITTER_CONSUMER_KEY']
config.consumer_secret = ENV['TWITTER_CONSUMER_SECRET']
config.access_token = ENV['TWITTER_ACCESS_TOKEN']
config.access_token_secret = ENV['TWITTER_ACCESS_TOKEN_SECRET']
end
end
def tweet(text)
@twitter.update(text)
end
end
twitter = TwitterClient.new
loop do
response = RestClient.get('https://clinics.maimmunizations.org/clinic/search?location=&search_radius=All&q[venue_search_name_or_venue_name_i_cont]=&clinic_date_eq[year]=&clinic_date_eq[month]=&clinic_date_eq[day]=&q[vaccinations_name_i_cont]=&commit=Search')
html = Nokogiri::HTML(response.body)
sections = html.search('.justify-between')
sections.each do |section|
paragraphs = section.search('p')
next unless paragraphs.any?
title = paragraphs.first.content
clinic_information = {}
paragraphs.each do |p|
description, value = p.content.split(':')
next unless value
clinic_information[description.strip] = value.strip
end
appointments = clinic_information['Available Appointments']
if appointments.to_i > 0
twitter.tweet("#{appointments} appointments available at #{title}")
end
end
sleep(60)
end
There’s a new loop do call (similar to a while loop in other languages) which tells Ruby to run this block of code over and over again, and at the end of the scraping code a new sleep(60) to have it wait a minute before it moves on to scrape the page again. It also checks whether there are any appointments available using if appointments.to_i > 0 before tweeting. Ruby string interpolation makes it easy to include the appointment number and title of the clinic in the tweet by enclosing #{appointments} inside of a string.
Really that’s all it takes to make a bot like vaccinetime! This code is very close to the first iteration I wrote, although vaccinetime has grown a lot since then! Further things I’ve added include making many more site scrapers, remembering the results of previous scraping so that it only alerts when new appointments are added, and making the bot work with waiting room
systems. If you’re interested in exploring the full codebase, check it out on GitHub at https://github.com/ginkgobioworks/vaccinetime.
It’s been amazing to see the response to vaccinetime, with the bot gaining over 50K followers and even being featured on the local news. If you’re located in Massachusetts and need to schedule a vaccination appointment, I hope you find it useful too!
(Feature photo by Ivan Diaz on Unsplash)
