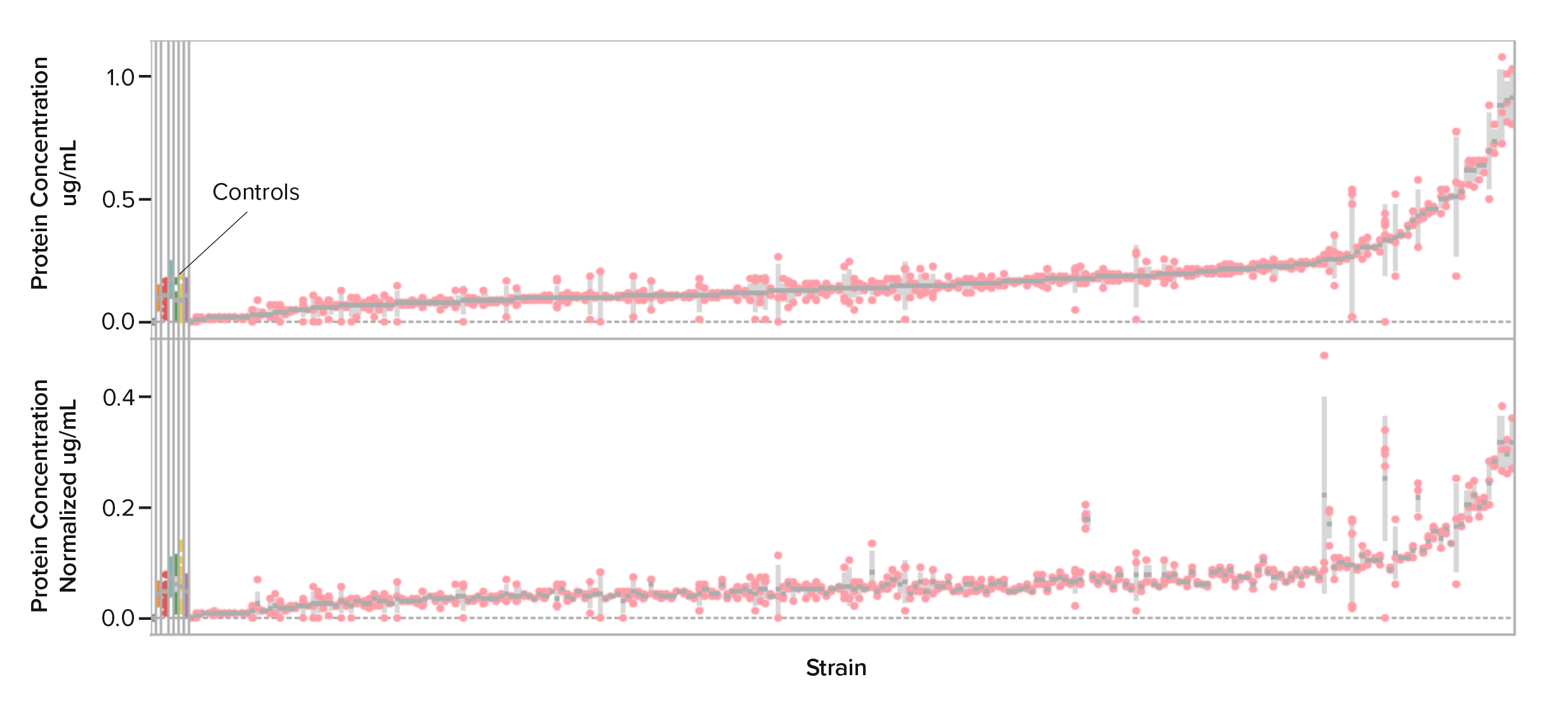
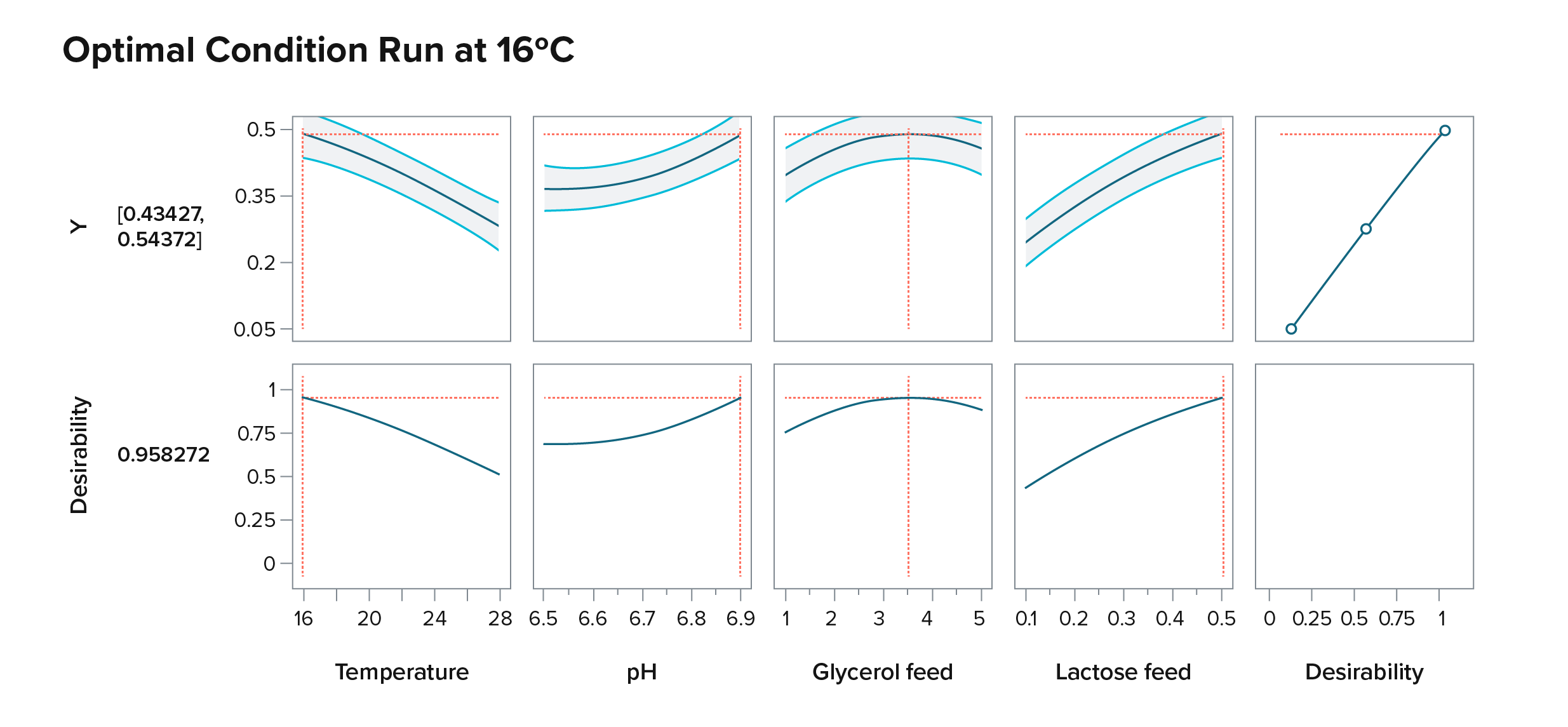
Yarrowia lipolytica has become a workhorse for metabolic engineering of molecules derived from fatty acids.
In cars, a chassis is a base frame to house the engine and working parts. Program Director Christian Lorenz discusses how Ginkgo developed standardized strains, workflows and DNA parts for the yeast Yarrowia lipolytica to help launch innovative biological engineering campaigns.
Humans of Ginkgo Bioworks is an interview series featuring Sudeep Agarwala interviewing some of the brilliant folks at Ginkgo to learn more about the technology that makes our work possible.
Sudeep Agarwala: I’m speaking from my personal bias, but when I think of yeast I usually think of Saccharomyces cerevisiae. Why is Yarrowia lipolytica such a powerful tool?
Christian Lorenz: Sure–I think there’s a good reason you don’t think of Yarrowia when someone mentions yeast. Most people would probably agree that Yarrowia is still a non-traditional yeast, but given how important it is in industrial biotech, there’s a lot more interest in the yeast for academic circles.
Basically, as the name suggests, Yarrowia lipolytica has been of interest because of its ability to accumulate lipids, or fat. We’ve seen natural strains accumulate 20 percent or more dry cell weight in lipids–I believe there are some reports of 40%, even. Some engineered strains can even have a higher content of fats. So Yarrowia is an expert in making fat and has a high flux through the fatty acid biosynthesis pathway.
This pathway is upregulated when the cells experience nitrogen limitation–there’s a starvation response that triggers lipid production. They utilize the carbon in the media, usually in the form of glucose, but in the industrial setting it can be something cheaper like ethanol, glycerol, acetate, or even different types of oil, and start accumulating fat, which are stored in lipid bodies in the cell.
SA: But there are a lot of yeasts that produce fatty acids–what’s so special about Yarrowia that it’s able to do it at such high levels?
CL: This is something that’s in common with an entire family of oleaginous yeasts, they’re called. In these yeasts, the precursors for the fatty acid synthesis pathway–acetyl CoA, which converts to malonyl CoA. In oleaginous yeasts, citrate is produced in the mitochondria; it is shuttled into the cytosol, where an enzyme, ATP citrate lyase, converts it into acetyl CoA, which leads to fatty acid biosynthesis. The flux through this pathway is much higher in these yeasts.
SA: This lifecycle seems pretty great for metabolic engineering — I know Yarrowia’s a workhorse for metabolic engineering off the fatty acid production. And in protein production, it’s great for lipase production.
CL: Lipases, and a lot of other hydrolytic enzymes too. But there’s an interesting use in small molecule production as well: because of the metabolism, Yarrowia is a good acid producer and that usually means that it can tolerate low pH in fermentation. That’s important because for some yeasts, they die at low pH. So when you engineer these yeasts for some small molecules that drop the pH, you have to add a lot of base to your fermentation. That’s not the case for Yarrowia, which we’ve seen do well as low as pH 3, even.
SA: That’s the good — I want to talk about the ugly, though. Yarrowia is known as a dimorphic yeast, meaning it has ovoid cells, but can also form these filaments that can cause real issues when it comes to fermentation. How do you deal with that?
CL: This is a really good point. First of all, we have a collection of more than 30 different naturally-occurring strains of Yarrowia at Ginkgo that we’re allowed to engineer with. Each of these strains are Yarrowia lipolytica, but they differ a lot in how they behave in how we engineer them, and how they behave in different fermentation processes. So for any particular engineering project, we have a wide choice of strains that we can test to see which ones will behave the best in our process.
SA: I feel like we’ve buried the lede — Ginkgo has more than 30 different wild Yarrowia strains?
CL: Sorry — yes. More than thirty, and we’ve gotten them being very careful about restrictions on freedom to operate and IP restrictions. And we’ve done a lot of work characterizing them: there’s the obvious questions about how they behave on solid medium on a petri dish vs how they grow in a liquid medium. But we’ve tested them further: how much flux do they have through the fatty acid biosynthesis pathway? In different fermentation conditions how tolerant are they to different process conditions? how well do they tolerate different pH? etc. We’ve gained quite a bit of information for them, so we can make intelligent decisions about how we deploy them in different engineering projects.
SA: What does it take to be able to genetically engineer more than 30 different Yarrowia strains?
CL: Well, we think about strain engineering in a Design-Build-Test-Learn cycle.
In terms of Design, we have standardized DNA tools that we know will work in most, if not all, of these strains. That is, we have standard promoters, terminators, drug selections on these engineering tools. And they’re targeted to parts of the genome that we know are easy to target.
That leads to Build, where we’ve developed methods of culturing and effectively introducing this DNA into these strains pretty effectively–transforming a wide range of these hosts in high-throughput is a pretty standard operation at Ginkgo.
For Test, like I mentioned before, we have a good understanding of how these strains behave in a wide variety of conditions–liquid media, solid media, and fermentation vessels. We know how to cultivate these strains in high-throughput so we can measure how much product–small molecule, protein, etc.–they’re producing.
SA: I hope you don’t mind the direct question, but at Ginkgo we refer to “chassis strains” when we’re developing an engineering plan. What exactly is the Yarrowia chassis at Ginkgo?
CL: I think we’ve done a good job summarizing that here, actually. A chassis is a frame or a housing for a piece of technology. Part of our engineering efforts at Ginkgo have been to make that framework in Yarrowia: we have strains, genetic tools for targeting and expressing DNA, protocols for building libraries of yeast strains in high-throughput, and protocols for testing these different strains in high-throughput. There will be some edge cases, always, but with these basic elements form a very powerful framework for biological engineering.
So when a new project comes in, we don’t have to think about developing things from scratch or bringing in new yeasts and spend a lot of time testing them or developing processes for them. Instead, we have our engineering chassis: we’ve built the engineering infrastructure for Yarrowia so that our customers can bring exciting products to the market fast.
 Christian Lorenz came to Ginkgo Bioworks after completing his PhD work on bacterial protein secretion systems with Ulla Bonas at Martin-Luther-Universität Halle-Wittenberg, and post-doctoral work on Pseudomonas aeruginosa in the lab of Stephen Lory at Harvard Medical School in Boston. At Ginkgo, he is an organism engineer specializing in metabolic engineering for small molecule production in bacteria and yeast systems.
Christian Lorenz came to Ginkgo Bioworks after completing his PhD work on bacterial protein secretion systems with Ulla Bonas at Martin-Luther-Universität Halle-Wittenberg, and post-doctoral work on Pseudomonas aeruginosa in the lab of Stephen Lory at Harvard Medical School in Boston. At Ginkgo, he is an organism engineer specializing in metabolic engineering for small molecule production in bacteria and yeast systems.
 Nádia Skorupa Parachin, Ph.D., is Senior Director of business Development at Ginkgo Bioworks, leading the Industrial Biotechnology sales team for the production of small molecules. Nádia brings over 15 years of experience in synthetic biology, metabolic engineering, and project management. She has previously served on the technical team at Ginkgo as a Senior Program Lead, engineering and delivering custom strains for Ginkgo’s partners. Before joining Ginkgo Bioworks, she was CEO of Integra Bioprocessors and a professor of biotechnology at Universidade de Brasilia (UnB).
Nádia Skorupa Parachin, Ph.D., is Senior Director of business Development at Ginkgo Bioworks, leading the Industrial Biotechnology sales team for the production of small molecules. Nádia brings over 15 years of experience in synthetic biology, metabolic engineering, and project management. She has previously served on the technical team at Ginkgo as a Senior Program Lead, engineering and delivering custom strains for Ginkgo’s partners. Before joining Ginkgo Bioworks, she was CEO of Integra Bioprocessors and a professor of biotechnology at Universidade de Brasilia (UnB). Sneha Srikrishnan is Senior Director, Business Development at Ginkgo Bioworks, leading Protein sales & Product management. She previously served on the technical team of Ginkgo as a Sr. Director of platform technology for enzymes and protein production. Prior to Ginkgo, Sneha worked at Gevo, Inc. as a scientist developing yeasts for commercial production of isobutanol. She has over a decade of industrial experience in successfully delivering synthetic biology-based solutions within the nutrition & wellness space, in sustainable fuels, waste valorization and environmental remediation, and holds patents in these areas. Sneha graduated with a Bachelors in Chemical Engineering from the Indian Institute of Technology, Bombay and earned her Ph.D. in Chemical and Biochemical engineering from the University of California, Irvine. Sneha is passionate about food security and circularity.
Sneha Srikrishnan is Senior Director, Business Development at Ginkgo Bioworks, leading Protein sales & Product management. She previously served on the technical team of Ginkgo as a Sr. Director of platform technology for enzymes and protein production. Prior to Ginkgo, Sneha worked at Gevo, Inc. as a scientist developing yeasts for commercial production of isobutanol. She has over a decade of industrial experience in successfully delivering synthetic biology-based solutions within the nutrition & wellness space, in sustainable fuels, waste valorization and environmental remediation, and holds patents in these areas. Sneha graduated with a Bachelors in Chemical Engineering from the Indian Institute of Technology, Bombay and earned her Ph.D. in Chemical and Biochemical engineering from the University of California, Irvine. Sneha is passionate about food security and circularity.