Automating the Creation of Batch Processing Workflows in AWS
TLDR
Imagine a Google Drive folder where dragging data into it not only stored the data, but also did work on it automatically, depositing the output into another Google Drive folder. Instead of Google Drive folders we’re using S3 buckets which are roughly AWS’s version of a Google Drive folder. At Ginkgo, we developed a service called “Shepard”, and it is basically a machine for making these setups. It’s a lot more than that but at its core that’s what it is. Shepard in its entirety is a constellation of tools, code and automation that orbit around that core concept.
Background
Ginkgo is a fast-moving company. When I joined the company around a year ago there was a need to quickly build automated analytical pipelines that were robust and could meet really challenging and diverse production requirements. I had gotten a reputation for building these pipelines but oftentimes a turnaround time of a month was too long to meet the needs of our scientists who within a week or so often needed to move on to another analysis. It quickly became apparent that the company was in need of an automated way to set up analytical pipelines quickly.
It was that need that led to a very intense two months of development for a solution to this problem. The problem I set out to solve was to build a method for automating the creation of analytical pipelines that:
- Any member of the DevOps team could use to easily build an automated analytical pipeline.
- Allowed end users to fully and easily batch out and monitor jobs and manage code deployments.
- Was flexible enough to meet all the potential configurations that had been seen up until that point and those that I imagined could potentially be requested in the future.
- Had rapid stand-up and tear-down times.
Result
Through Intense development and the incorporation of all the previous lessons we learned at Ginkgo, we developed an architecture called “Shepard” (named after the astronaut).
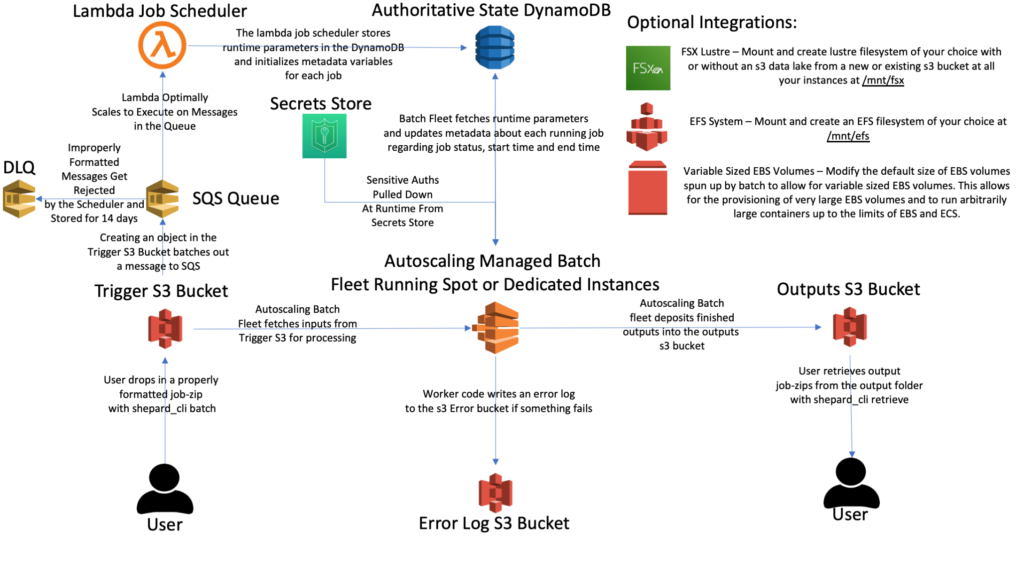
Shepard is a CloudFormation template and an accompanying custom-made CLI. The architecture enables automatic and easy execution of arbitrary container code against uploads of any size to an S3 bucket. Running in a standard account Shepard can turn over 17,500 uploads to an S3 bucket into batch jobs a minute and can queue to over 120,000 jobs simultaneously at any one time (although this number can be raised to an arbitrarily high number by chaining together SQS dead letter queues and giving said queues event mappings to execute the scheduler lambda which is not hard to do although it makes the diagram look ugly). This means it takes a little over 57 minutes to turn 1,000,000 uploads into AWS Batch jobs. It provides options to create AWS EFS and/or high-performance AWS Lustre file systems and automount them to worker containers and has options to securely store and interact with authentication tokens and other sensitive cryptomatter stored in AWS Secrets Manager. It comes with a command line interface that allows users (among other things) to easily batch out jobs, deploy new code, query existing jobs and deploy authentication files and cryptomatter to secrets manager each with a single command. Shepard also supports the usage of Spot or EC2 instances for its batch jobs and automatically configures launch templates that allows for the running of instances with arbitrarily large EBS volumes and can run arbitrarily large containers. This same launch template magic also allows for the raising of the maximum number of open files up to 10242.
A whole architecture can be built or deleted in under a half hour. You can build as many architectures in parallel at once in AWS. The CloudFormation template it uses is self-contained, so it requires no external dependencies. Moreover, the part of the architecture that builds first (the ECR repo) is the part you actually upload code to. It often takes a while to build a container and push it to ECR but you can start this process the second you start building the CloudFormation. Providing building and pushing your container to ECR takes less time than it does to build the architecture by the time the CloudFormation finishes building you could be ready to immediately start running jobs. I’ve set up many fully completed functioning architectures in as little as 20 minutes.
Enough of my talking though; I’d rather show an example of how easy it is to code something on Shepard by walking through the code I use for testing.
Let’s say I had a directory that contained a Dockerfile as seen below:
# Testing for Shepard # Author: jmevorach ########################### ESTABLISH BASE IMAGE ################################## FROM ubuntu:bionic MAINTAINER [email protected] # --------------------- # APT GET UPDATE # --------------------- RUN apt-get update -y # --------------------- # Python stuff # --------------------- RUN apt-get install -y python RUN apt-get install -y python-pip RUN apt-get install -y python3 RUN apt-get install -y python3-pip RUN apt-get install -y python-dev RUN apt-get install -y python3-dev # --------------------- # Get tree # --------------------- RUN apt-get install -y tree # --------------------- # Entrypoint & Default cmd # --------------------- COPY testing_code.py / WORKDIR / ENTRYPOINT ["python3"] CMD ["testing_code.py"]
And I had a testing_code.py file that looked like this:
# By Jacob Mevorach for Ginkgo Bioworks 2020
import os
import logging
def main():
logging.log(level=logging.ERROR, msg=os.getenv('test'))
if os.getenv('USES_LUSTRE') == 'True':
os.chdir(os.getenv('LUSTRE_OUTPUT_NAME'))
os.system('dd if=/dev/zero of=outputFile bs=2G count=1')
if os.getenv('USES_EFS') == 'True':
os.chdir(os.getenv('EFS_OUTPUT_NAME'))
os.system('dd if=/dev/zero of=outputFile bs=2G count=1')
return 0
if __name__ == '__main__':
main()
And then I ran “shepard_cli deploy” against the directory with the Dockerfile and testing_code.py in it then ran a payload by using the following inputs.txt with either:
- the “shepard_cli batch” command
- by dragging a zip containing the file into the S3 bucket directly
- or by dragging a zip containing the file into a folder placed anywhere that had been linked up to the S3 bucket via Storage Gateway.
{
"test": "This will become the value associated with an evironment variable named 'test'",
"tag": "this_will_become_a_prefix_for_outputs"
}
I would get the following output in CloudWatch:

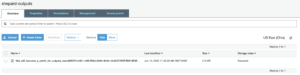
Let’s unpack what just happened here because it will illustrate a couple of concepts about Shepard. First the Dockerfile I built downloaded what it needed to run Python on an Ubuntu container and then added a testing script which it set to run as its default command. I used Python here but I could easily have made this container anything and had it run any sort of code. I could have just as easily downloaded 20 different scientific programs to another OS container and then set the container to run Go code.
Then I deployed that code to Shepard and when I ran my testing payload my code logged the environment variable associated with the name “test” which (as seen in the JSON) was “this will become the value associated with the environment variable named ‘test’” and it showed up in my CloudWatch logs.
Shepard automatically configures a bunch of useful environment variables with metadata about the architecture code is running on. In this case my code used some environment variables that say whether or not my architecture uses EFS or Lustre. In this case my architecture uses EFS but not Lustre so my code detected that that was the case using environment variables and then wrote an output file of zeros to the designated output location on the EFS described by the environment variable called “EFS_OUTPUT_NAME”.
The outputs written there (in the case just the single file of zeros) was uploaded to the output S3 bucket when the code finished executing and because I specified a “tag” variable in my input.txt this “tag” has been appended as a prefix to the name of my outputs. You can see this in how the name for my output starts with “this_will_become_a_prefix_for_outputs” which was the value I gave to “tag” in my inputs.txt. And while the file name is very long at the end of it is the suffix “_efs” which reflects that this is an output that came from the output location specified by “EFS_OUTPUT_NAME”.
This is a trivial and simple case but in real life what I could do is run heavy scientific workloads that do I/O intensive operations on Lustre and store large output files on EFS and then have those automatically uploaded to S3 with an easy to find name. Moreover if I was a developer who had just read the documentation on how to use Shepard I could do this without any real understanding of how to set up or provision a file system or mount it to a container running on an EC2 instance with a launch template. The idea is that people can approach this architecture and write code and run it and get useful outputs without having any idea about how to set up the infrastructure.
Shephard CLI
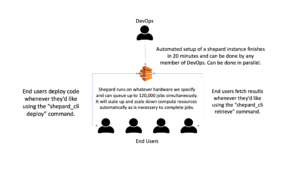
Shepard comes equipped with a CLI (command line interface) that allows users to easily interact with as many architectures as they’d like to. It can be installed in 4 lines from our company’s git repository and only requires that Python, Docker and Git be preinstalled on a user’s computer as prerequisites prior to the installation process. The CLI is installed using pip and is then available for calling from any directory on the computer like any other CLI.
 Some Creative Applications
Some Creative Applications
Linked Architectures For Rapid Job Processing on Data From an Online Database
A very common problem in genomics involves processing FASTQ datasets from an online database such as the National Institute of Health’s SRA database. To download datasets like this you’d want containers operating on a networked instance that can get to the internet. However if you have limited IP space in your account (which is often the case) it would often allow for much more rapid processing if you could decouple the dataset collection and processing from one another.
A great solution to this problem would be to use two Shepard Architectures that are linked to one another. You’d want the first architecture to be networked so that it could download files from the online database and you’d want the second architecture to use a non-networked VPC. which will allow for the spinning up of as many instances as you can until you hit your service limits. The first architecture would contain AWS access keys in its secrets manager that would allow it to dispatch jobs to the second architecture. When you submit a job to the 1st architecture (which is networked) it runs a job that collects a dataset and submits it to the second architecture for processing (which is not networked) using the AWS access keys in its secrets manager to access the input S3 bucket of the second architecture.
The idea here is that while you’re able to spin up fewer EC2 instances in the first account (which have to use networked IP space) the jobs performed there to fetch data execute in a shorter time than the processing jobs on the second architecture (which does not have to use networked IP space) where you can spin up very large numbers of EC2 instances comfortably. This allows for the decoupling of the download and processing aspects of a workflow across two architectures and allows the subprocesses to scale up or down independently of one another. This frees your processing containers from having to use precious networked IP space in a VPC and allows for the mass processing of datasets from an online location using non networked compute resources.
Interactions with Third Party Services
You can also very easily put slack credential or G Suite credential objects into secrets manager for use with your architecture. This allows for things like jobs that send slack notifications or jobs that parse Google Sheets for inputs (both of which I’ve done before). It can be really useful to have jobs that send alerts to people when they finish.
Planned Usage
A more senior DevOps engineer than myself estimated that Shepard could be used to automate around 60% – 70% of the workflows being done by scientists. Another (also more senior than myself) DevOps engineer expressed a desire to have somewhere between 70 to 80 Shepard architectures operating by the end of the year across our AWS accounts. It’s hoped that the modular and rapid deployment capabilities of Shepard lend itself well to the sort of fast paced rapidly changing analyses that Ginkgo tends to focus on.
That said the remaining 30% – 40% of workflows that Shepard can’t automate are mostly microservices and in that case it’s more like shouldn’t automate rather than couldn’t. Shepard allows you to specify in the input template a number of inputs that allow for the provisioning of static EC2 instances that just wait around the clock for jobs to come in. This could function as a sort of poor substitute for some microservice functions if you wanted it to but it would be an ill-suited substitute.
My ultimate vision is that the following three projects could be completed which would allow coverage for basically everything that Ginkgo (and many other companies I assume) would ever want to do:
- Shepard which is as described in this post and is already completed.
- A version of Shepard but that runs datasets on AWS HPC (high performance computing) rather than AWS Batch. This would allow for the use of a cluster to run jobs on which allows to aggregate the resources of multiple instances rather than relying on the resources in a single instance.
- A plug-and-play Shepard style architecture but for microservices.
I’d also love to open source one or all of these in the meantime provided I get permission to do so. I think it’d be imminently useful for all sorts of people.
Plea to AWS or Any Cloud Service Provider Listening
If you offered an officially supported service that is something like Shepard (or for that matter any of the three projects I named in the “Planned Usage” section) I think it would be great and also make good business sense to you. So much duplicated effort has been done across companies to accomplish those three things that if you offered out of the box versions of those workflows people would flock to use those services. It’d be great for getting people into the other services that are in the ecosystems of those workflows as well (i.e. Batch, Lustre, EFS, etc. etc.). You could basically have companies automate most of their workflows because it’s an easy platform for developers (even with little to no cloud experience) to write on and use and you just need a few DevOps engineers or people with cloud experience to know how to rapidly set up architectures. I’m sure that if someone at AWS wanted to build a better, officially supported version of Shepard that builds upon what I was capable of creating on my own they could very easily do so and I would be exceedingly happy if that were to happen.
(Featured photo of Alan Shephard, commander of Apollo 14, courtesy of NASA.)
