It’s that time again! Our Digital Technology Team interns have wrapped up another successful summer. This is the first in a three-part series where our interns tell you about their work. We start with Roshida and Sean.
Roshida Herelle, Product Design Intern
Introduction
Hello! My name is Roshida and I am a rising Junior pursuing a Bachelor’s Degree in Technology and Information Design at the University of Maryland, College Park. This summer I have been working as a Product Design intern on the Product Design team!
Project
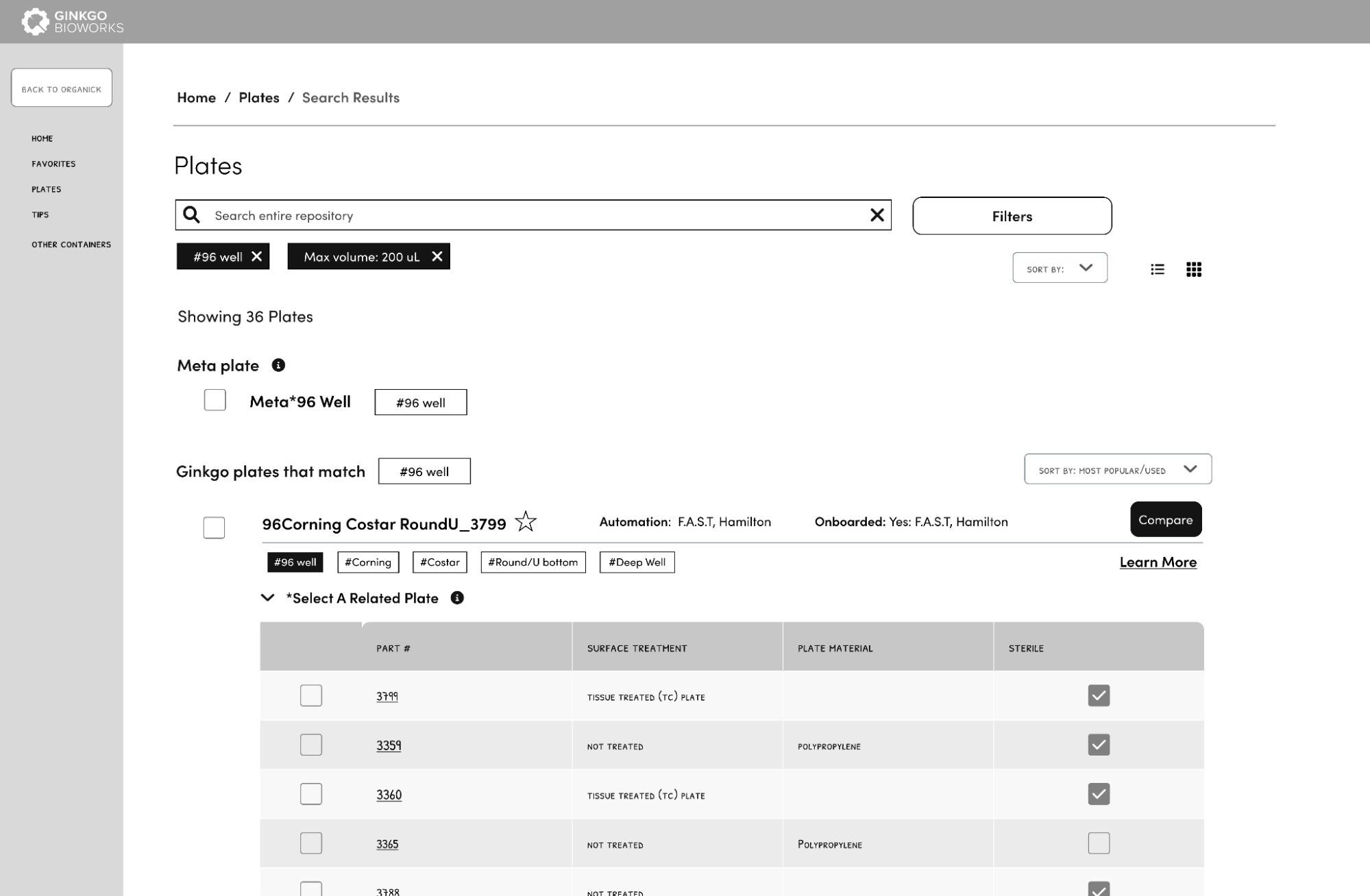
My summer project was to create the interface for a plate repository that scientists can use to identify and learn about the plates they use for their experiments.
Plates are used to hold samples and are arranged in grids that contain wells. Plate characteristics, such as well number, well bottom shape, maximum well volume, etc., can be influential to an experiment because they can affect things like microbial growth, liquid transfers, and other processes. This means plates can vary in a lot of different ways. At the moment, there isn’t a centralized location to see these characteristics or understand the differences between plates. Additionally, the naming schema of plates isn’t helpful to scientists because it’s inconsistent across plate types and lacks important information to guide scientists in their plate selection. Since this project will continue to develop after my internship, I was given the task of creating a new naming schema and foundational UI that will be expanded upon. I collaborated closely with Sean Doyle, a Software Engineer intern, who worked on coding the database and creating the API for the repository.
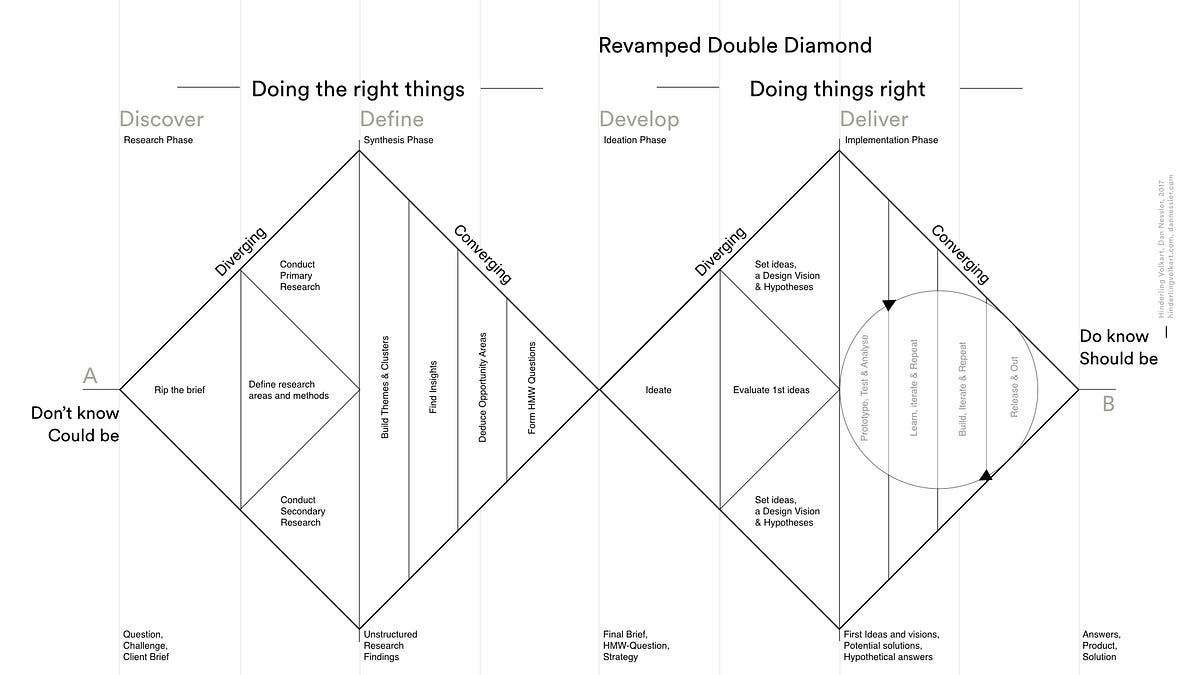
My design process followed the double diamond method. This approach helps us thoroughly understand design problems in order to brainstorm innovative ideas and deliver a satisfactory product solution.
Through discovery user interviews, we found that scientists use external resources, such as manufacturer sites and Google spreadsheets, to find information about plates since they don’t have a single source of truth for plate types and their details. Additionally, the inconsistent plate naming schema confuses scientists because they’re not sure if what they’re selecting actually matches a plate in the lab.
After conducting this research, our defined problem statement was that the current plate selection process requires a lot of mental and physical labor from scientists because their decisions are not thoughtfully guided.
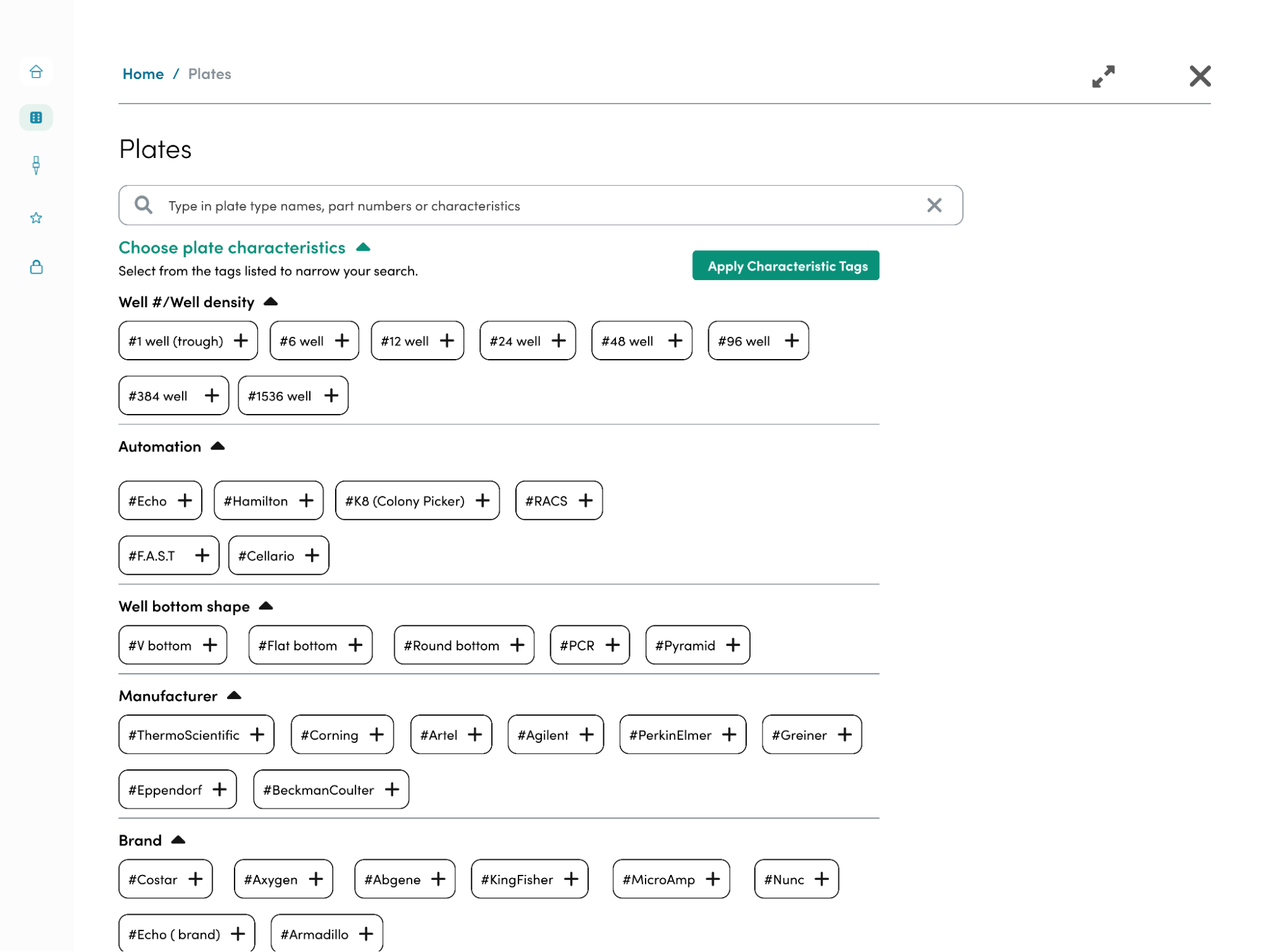
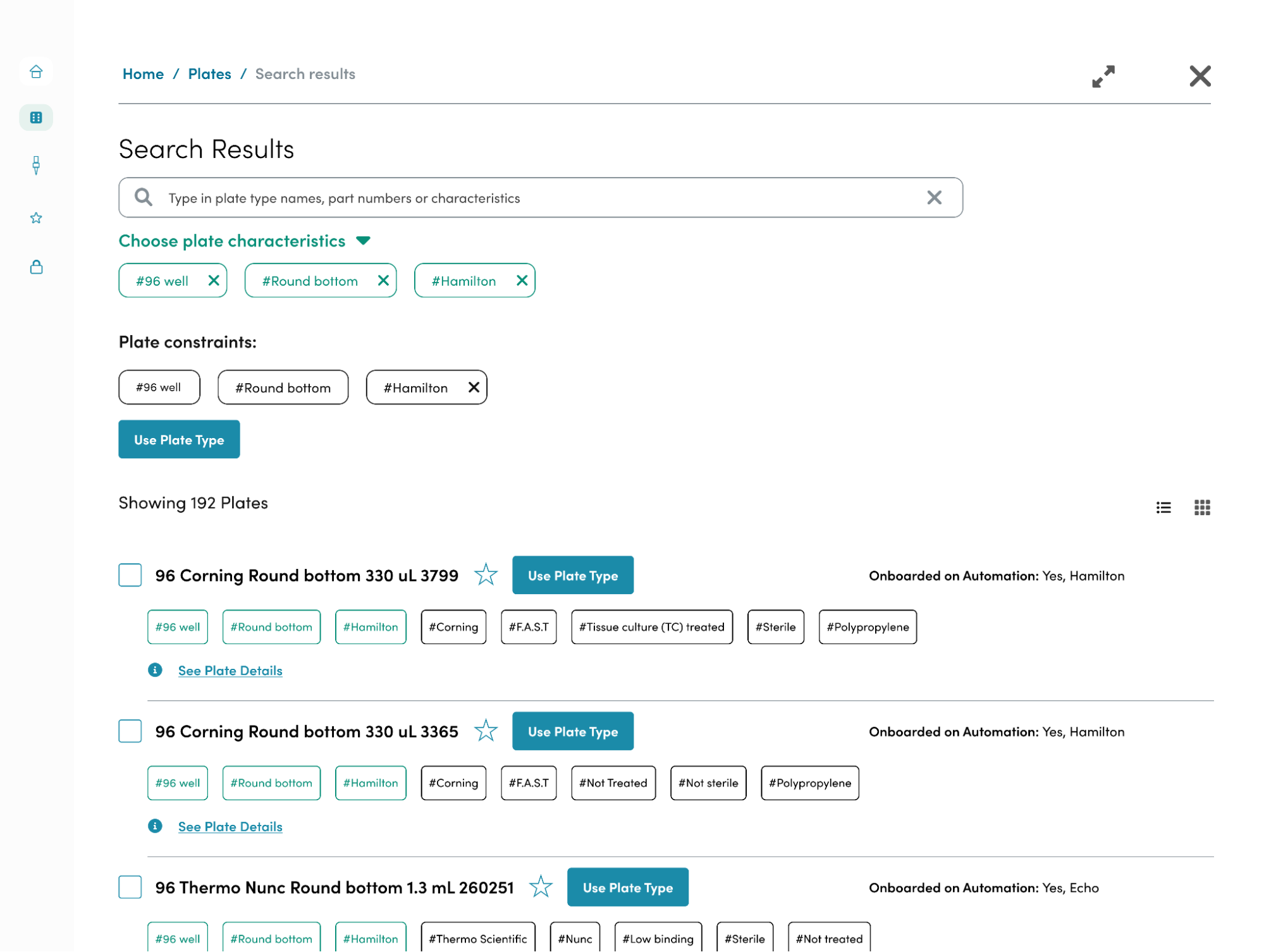
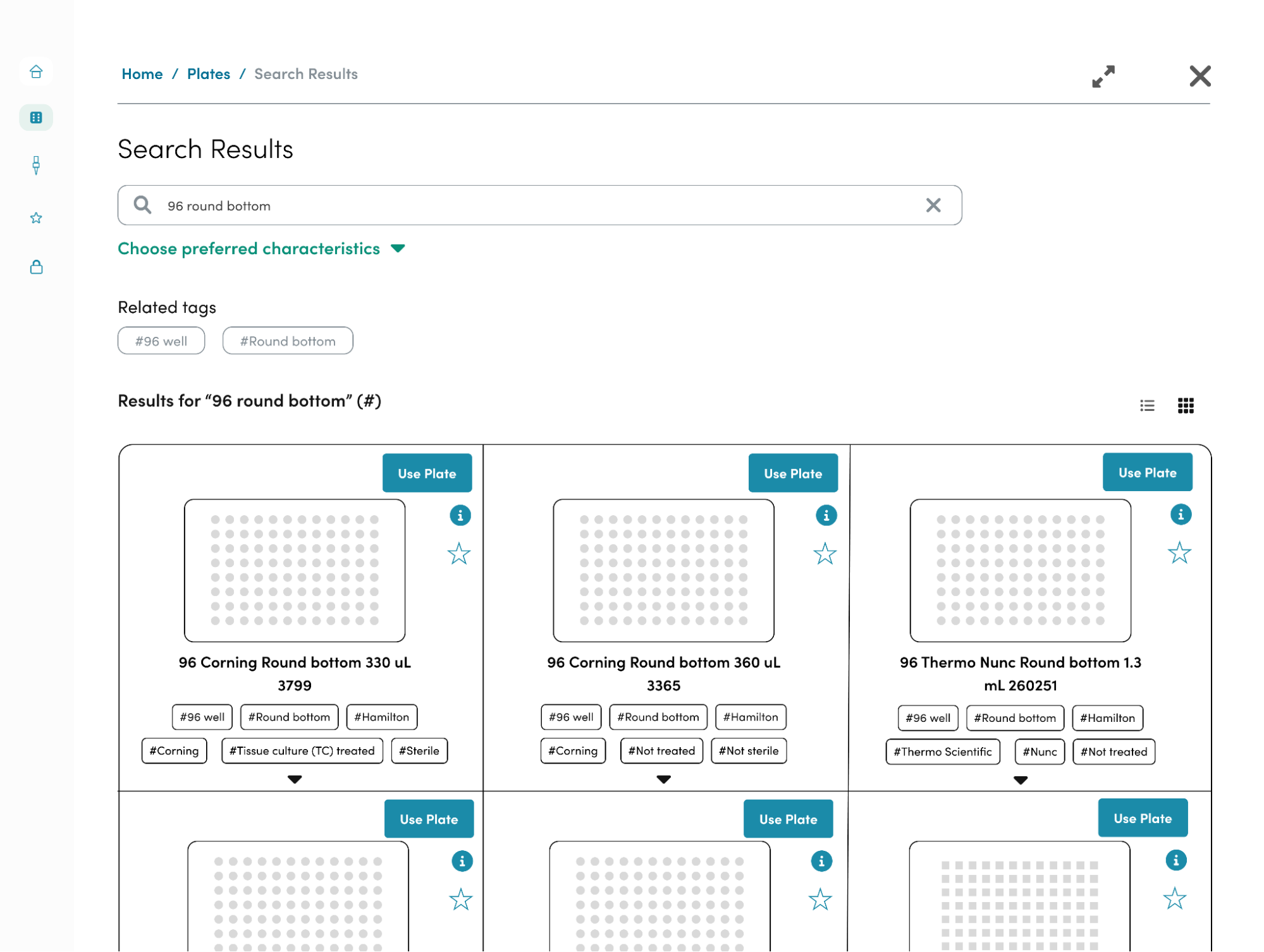
Taking these findings, I brainstormed some design solutions and low fidelity screens that I brought to the team for feedback. Our main solutions were to 1) standardize the naming schema to be consistent and informative 2) create a way to filter beyond automation choices 3) show users which plates are similar and different 4) allow the automation team to onboard new plate types into the repository. We wanted this tool to be accessible through the software tools that we’ve built at Ginkgo to enable scientists to access the repository whenever possible.
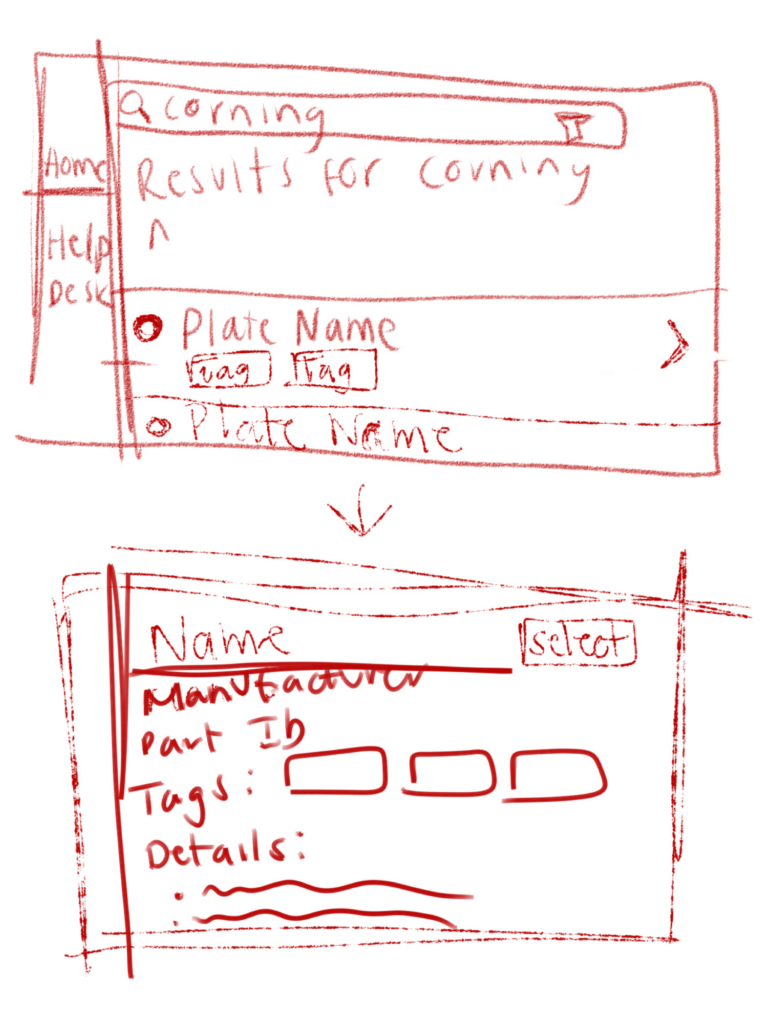
While brainstorming naming schemas, I conducted a closed card sort. A closed card sort is a user research method where you have participants group cards into predetermined categories to better understand their mental models. In this instance, the cards were plate characteristics and the categories were “need to know in a name”, “nice to know in a name”, “don’t need to know in a name”. After testing different naming schemas, we settled on including well #, manufacturer, brand, well bottom shape, volume, and part number because users felt that it was descriptive enough to visualize and locate it in the lab.

Afterwards, I created user flows and sitemaps to guide my information architecture and interface design. I developed mid fidelity screens that I tested with users to get feedback.
Using their feedback, I mocked up the following high fidelity screens that were iterated on after another round of testing.
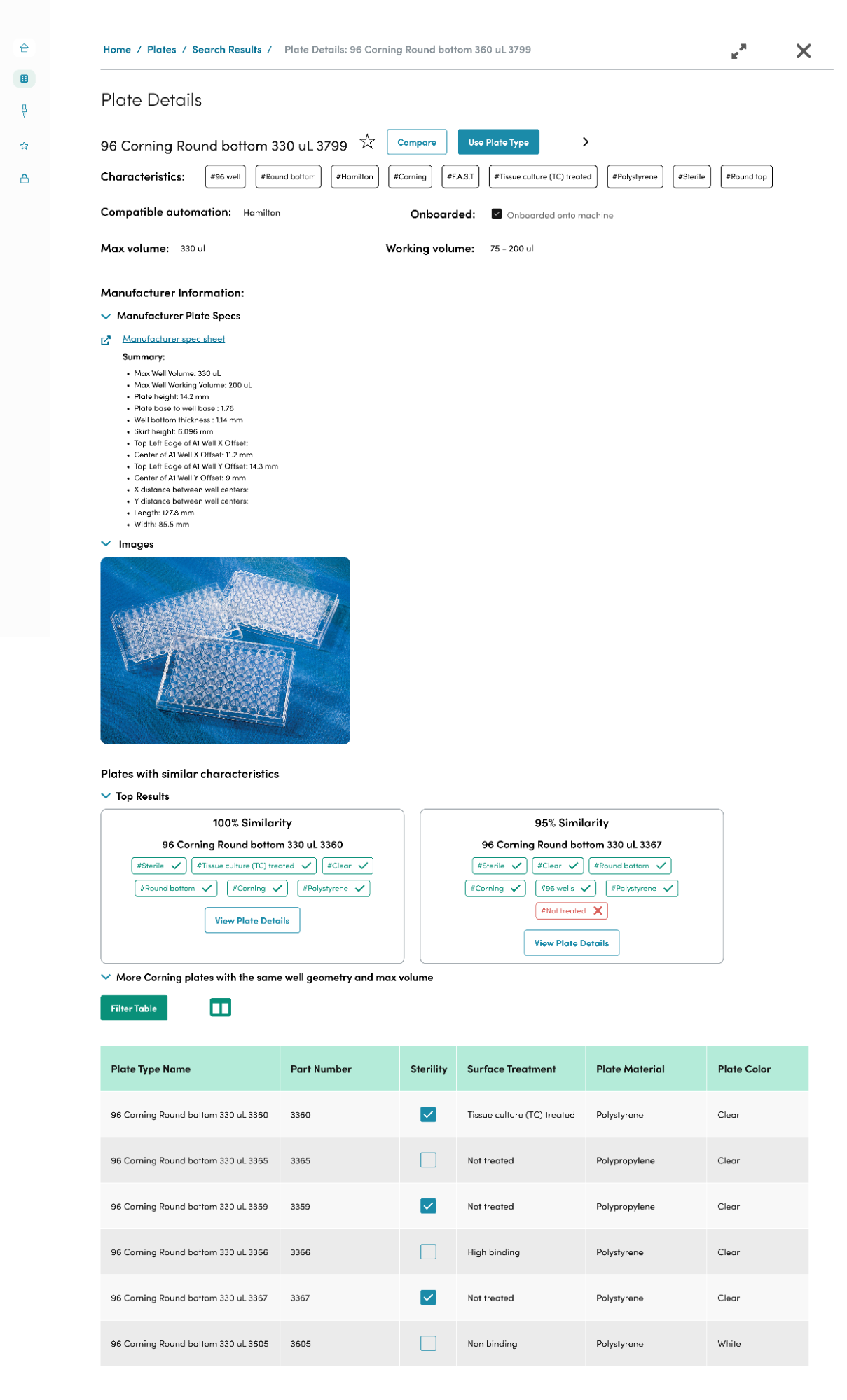
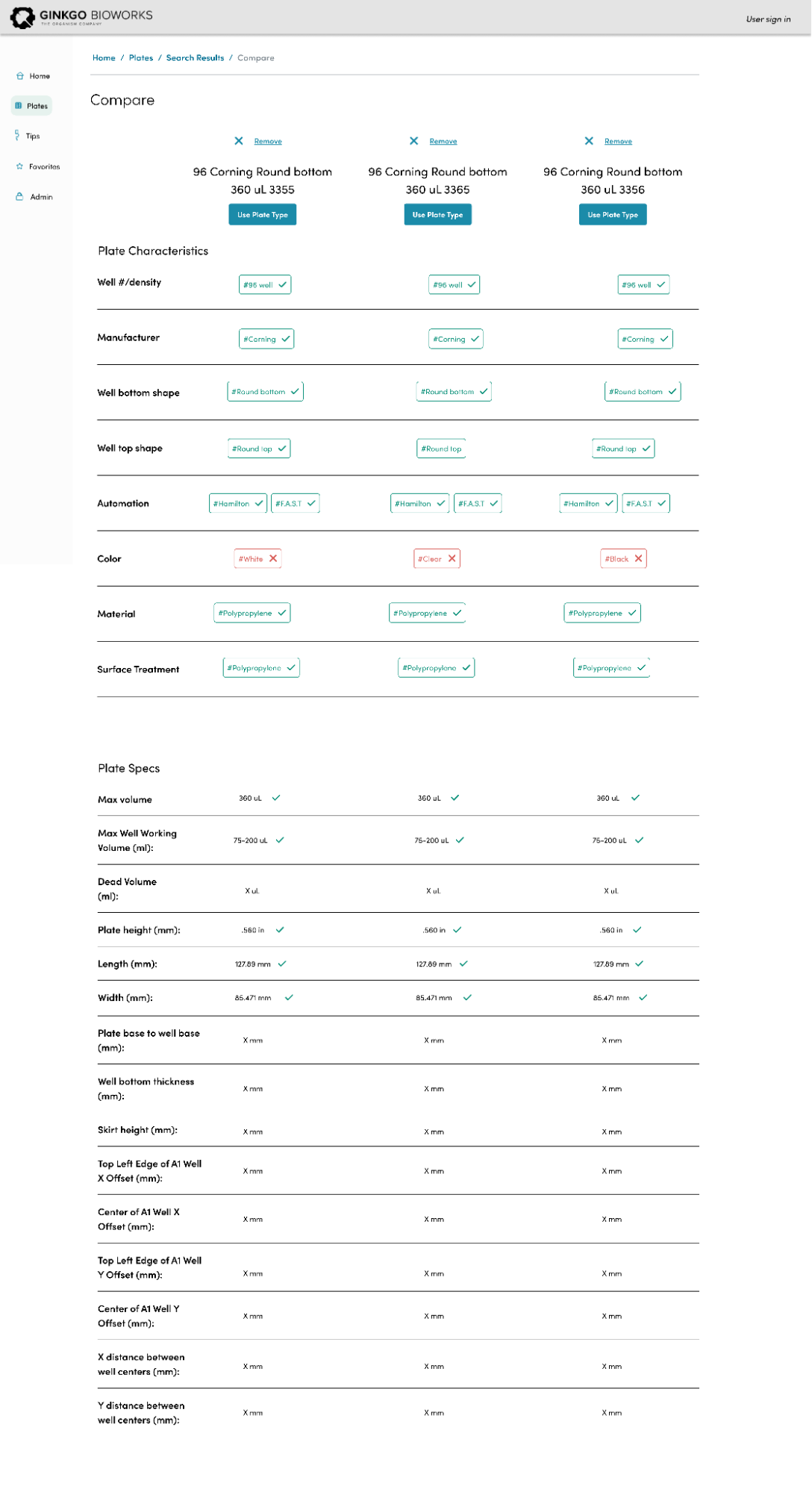
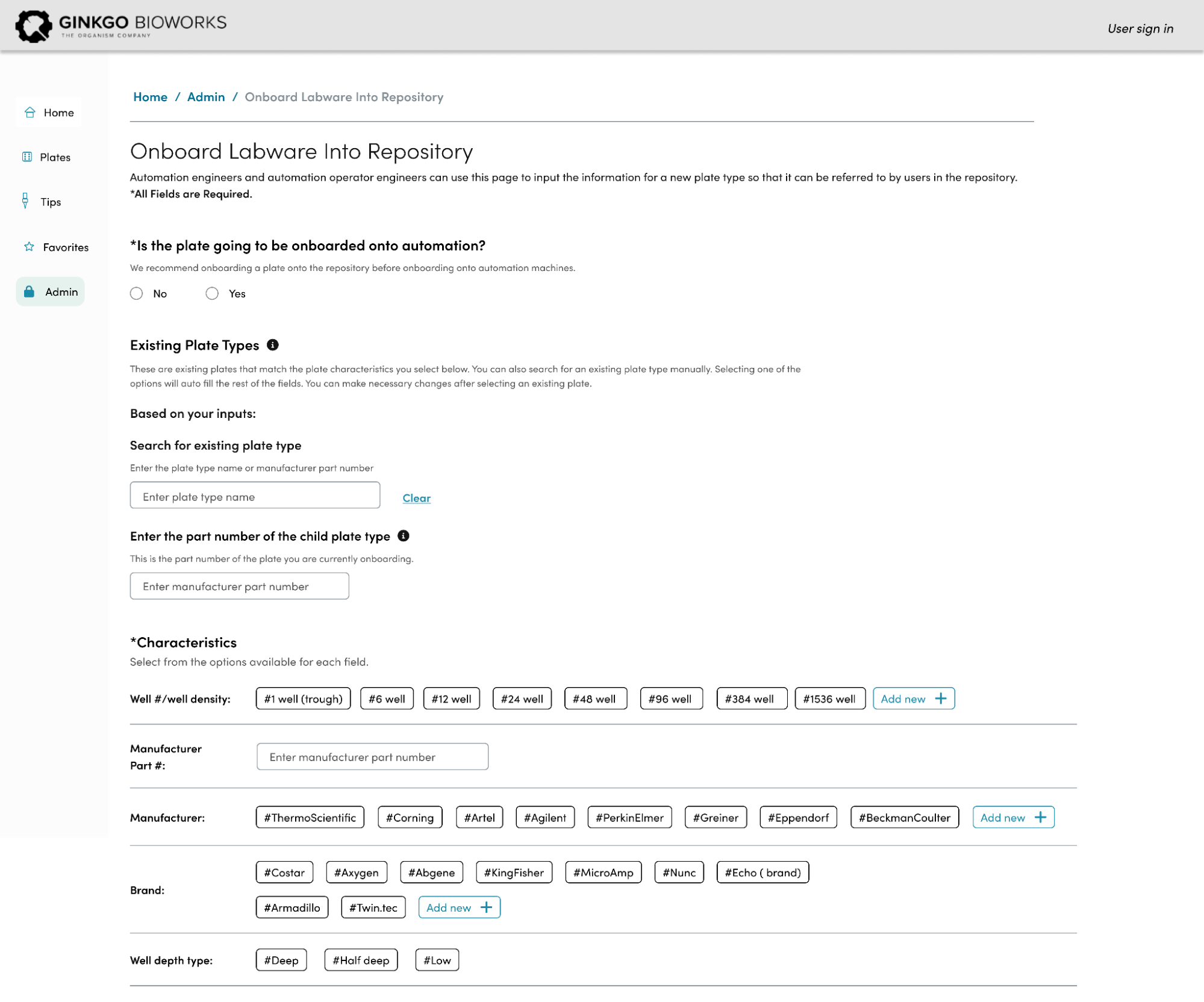
End Result
My initial design solutions weren’t perfectly executed at first, and required a lot of iterations and testing to figure out an interface that wasn’t only satisfactory to myself but to the scientists who will eventually interact with this tool. Overall, I’m satisfied with the end result! Scientists found my final mockups and naming schema to be intuitive, informative, and believed it would help speed up their processes of finding a plate.
Ginkgo Experience
Though I spent a lot of time working on my project, I made sure to have some fun as well! Thanks to our Early Talent event coordinators Eddie Kaikai, Angela Perkins and Casey Wheeler, I was able to partake in intern bonding events like the Red Sox game and Intern Trivia Night. I want to give a BIG shoutout to Cynthia Pollard and Hanna Tseng for being the best mentors throughout my time at Ginkgo and making me feel supported the entire way. I also want to thank the Product Design, Product Management, Software Engineering and Automation teams for their contributions to this project and their willingness to help me bring my design vision to fruition! It was amazing to work on such a high impact project for my first internship and I can safely say I’ve developed irreplaceable skills that will help me grow as a Product Designer and individual. If I could pinpoint where I’ve grown the most, it was certainly at Ginkgo!
Sean Doyle, Software Engineering Intern
Introduction
Hello, my name is Sean Doyle and I am a rising senior at New York University studying Computer Science. I spent the summer working on the Automation Integration team as a software engineering intern and got a chance to apply my previous software engineering experience in robotics, AI, and embedded systems to the new domain of lab information management within automation! Big shoutout to Vichka Fonarev, my mentor for the summer, who helped tremendously with not just my project but also my personal growth and learning!
Main Project
Problem Statement
My main project for the summer revolved around a critical piece of labware called a “plate”.
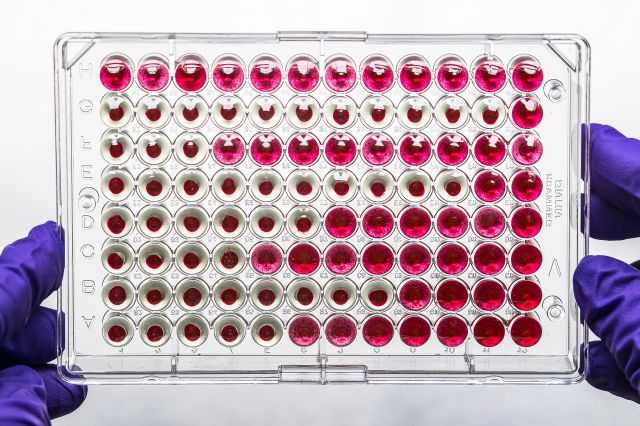
Plates are made up of a number of wells that store samples as they are processed through a biological procedure. They are the most important piece of labware that scientists across Ginkgo use to run their experiments and over 500 plate types have been onboarded at Ginkgo to accommodate a wide range of applications. With that said, information on the characteristics and automation compatibility for each plate type is siloed across services and people making it difficult to retrieve. This information is critical to different users, ranging from a method developer choosing a plate type that works with the proper automation, LIMS (Lab Information Management System) setting up a container with the correct plate type name and number of wells, or an automation engineer onboarding the dimensions of a plate type onto a new liquid handling robot. An inability to find these characteristics on a plate can cause critical issues such as assay failure from plate type and automation instrument incompatibility, operator confusion from vague plate type names, or automation crashes from imprecise plate type measurements. My project for the summer was to develop a service to solve these problems regarding information retrieval on plate types.
The Solution
The solution I developed is called the Labware Repository Service (LRS). It is a centralized single source of truth database that holds critical information on plate type characteristics and can integrate across platforms at Ginkgo.
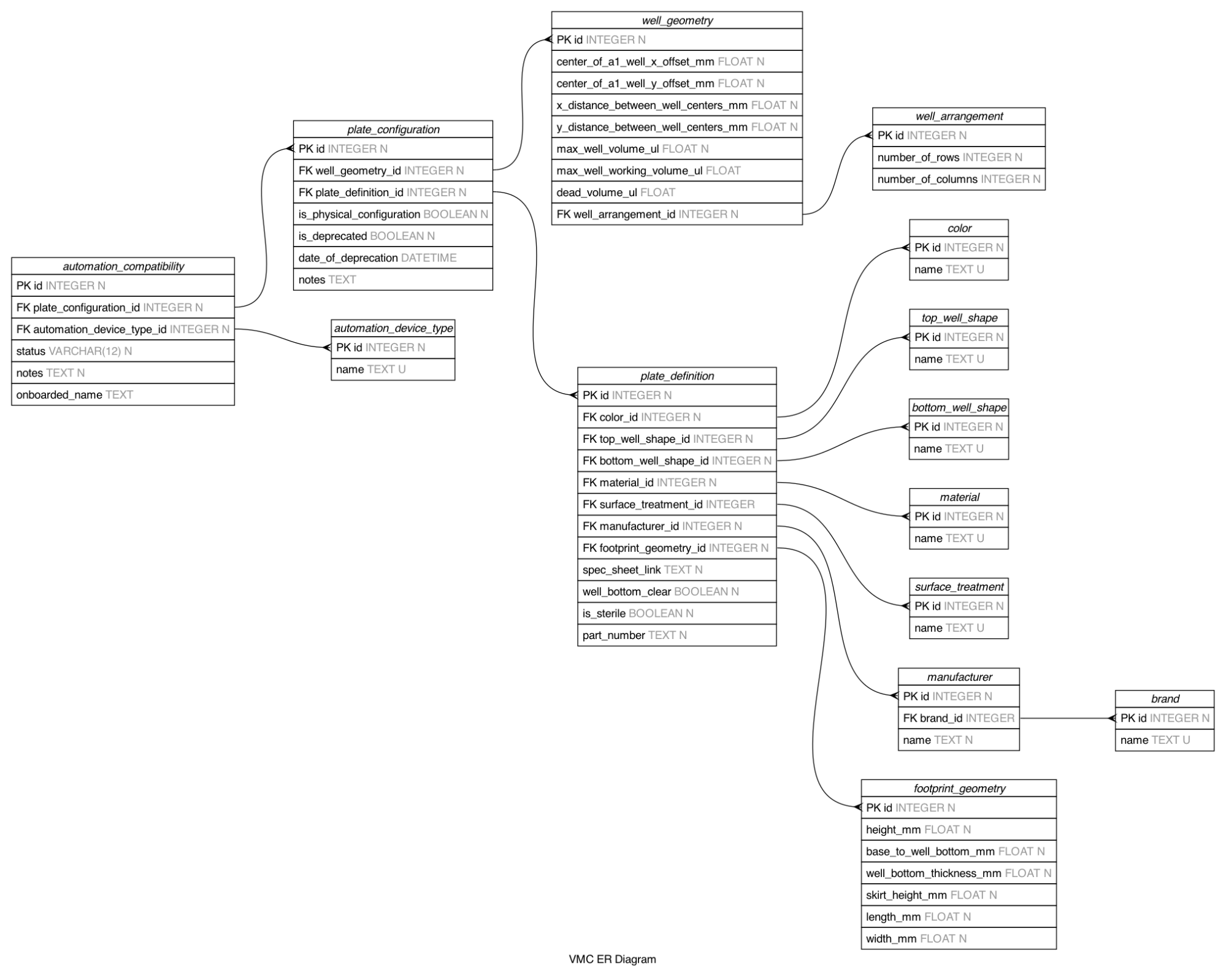
The LRS is a backend service configured with a parameterizable API that can interface with user facing applications. The most important of these applications is the Plate Repository User Interface(UI) which is a front end service that fellow intern Roshida worked on this past summer. The Plate Repository UI allows method developers and operators to filter through the LRS database to find the right plate for their procedure. The filtering options include a number of characteristics ranging from, number of wells, automation compatibility, color, well volume and much more, all of which are stored in the LRS database. Furthermore, the LRS API provides a way to enter a new plate type, validate the entered characteristics, and ensure that duplicate plate types are never created. These features will be critical to ensuring data integrity as users interact with the LRS through the Plate Repository UI.
A number of different technologies were chosen to implement the LRS. PostgreSQL is the standard database management system at Ginkgo so it was used alongside SQLAlchemy to create the database models. Since the primary user of the database is the Plate Repository UI, GraphQL was chosen as the main API endpoint to access the database as it interfaces well with React UI applications. Additionally, GraphQL is a unified standard that other internal Ginkgo tooling uses so future integrations can easily accommodate the LRS as first party data. A set of REST endpoints were developed to interface with embedded systems in automation that cannot easily send GraphQL requests. Docker was used to containerize the LRS to make both deployment and development across platforms easier. The LRS was deployed on AWS Elastic Container Service (ECS) alongside the PostgreSQL database which was deployed on AWS Relational Database Service (RDS) both using infrastructure as code.

Impact of Work
There was a lot of ambiguity and conflicting information surrounding plate types which made this project difficult but rewarding. I got the chance to contribute to the product development team’s user interviews and it was illuminating to see just how differently people thought about plate types across the company. For example, an automation engineer needs to know precise plate dimensions to enter onto a robot, operators need to know about plate opacity for optical density readings, and method developers need to know how many wells a plate has so they can test their samples efficiently. Everyone’s perspective was valuable so I continuously looked for feedback on my planned database designs to meet all users’ needs with the simplest solution possible. Almost everyone I talked to mentioned how impactful the LRS would be to standardizing information about plates and was excited that someone was finally taking on the challenge. From reducing downtime due to operator confusion, to promoting automation and work cell adoption, to expanding the capabilities of automated instruments, the information stored in the LRS will impact a diverse set of users. It was humbling to be entrusted with such an important project that had far-reaching implications across Ginkgo. Additionally, this project was one of my team’s first exposures to GraphQL so it felt particularly meaningful to learn this new technology alongside my team and then contribute to my team’s shared understanding of it. Building a service from the ground up was satisfying especially knowing how expansive it was to become in the future as it integrates across existing integral services.
My Ginkgo Experience
This whole summer was a blast! During an intern event a presenter said that Ginkgo likes to hire “smart friendly people” and that really resonated with me. Whether it was shadowing operators in the lab, biking 35 miles one Sunday with a few other interns, or just random check-ins from my team offering to help me out or support my learning in any way they could, I felt like I was surrounded by role models throughout the summer. To me, the people I’m with are the most crucial factor for how impactful an experience is and rarely have I been surrounded by as many strikingly intelligent yet genuinely kind people as I have at Ginkgo. I’m very grateful for the summer I got to spend here and look forward to more memories with the lifelong friends I’ve made here!


Thanks for reading! Next time on GinkgoBits, Himanshu, Arijit, and Hunter will tell us about their summer!
(Feature photo by Saiph Muhammad on Unsplash)
