Background
Developing useful digital infrastructure can be hard. Writing digital infrastructure that others want to use is even harder. There’s a lot of concerns surrounding digital infrastructure and sometimes it can be difficult to satisfy the concerns of all stakeholders involved.
Architecture needs to be scalable, secure, cost-effective, easy to support, easy for developers to develop for, and a whole host of other things. Moreover, it often takes multiple types of architectures to satisfy a single problem.
The first architecture I wrote about for this blog was called Shepard. It was a highly scalable “batch-workflow-in-a-box” that I presented at AWS’s high performance computing event. (I had a lot of fun presenting by the way ,so thanks to everyone over at AWS!) and is now available for free for anyone to use as an open-source project. Fluoride is another architecture in that vein.
Project History
When I finished writing Shepard, I had said that my future goals included writing an architecture for microservices and another architecture for accelerating supercomputing workloads. So while Shepard is “batch-workflow-in-a-box”, Fluoride is a “microservice-in-a-box” and is a way for anyone, even people with very little DevOps or cloud experience (like many scientists or developers or assorted engineers) to easily stand up a highly scalable microservice and start routing requests to it.
What is Fluoride?
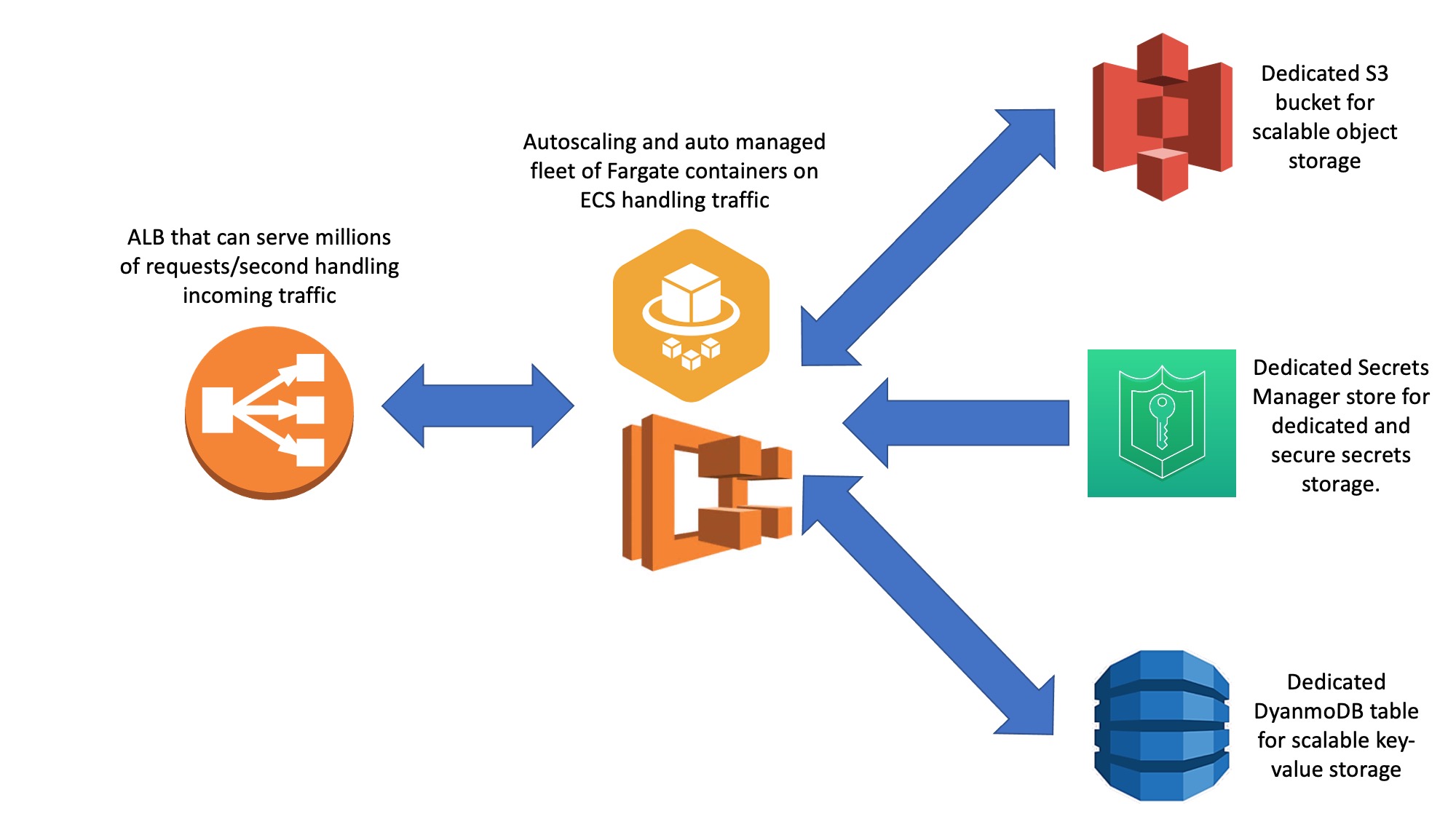
Fluoride is an architecture consisting of a CloudFormation template and an accompanying CLI I wrote. Using CloudFormation, a user can stand up an autoscaling Fargate cluster with really tight security groups, properly configured DNS, rollouts where if one fails the rollout will immediately roll back to the last stable deployment, health checks, detailed logging of all access attempts and containers, all nestled beyond an ALB that can field incredible amount of traffic.
Using the CLI a user can easily manage as many architectures of this sort as they’d like. Using single commands a user can easily push new releases to ECR and trigger deployments without really having to understand too much about how any of the backend really functions.
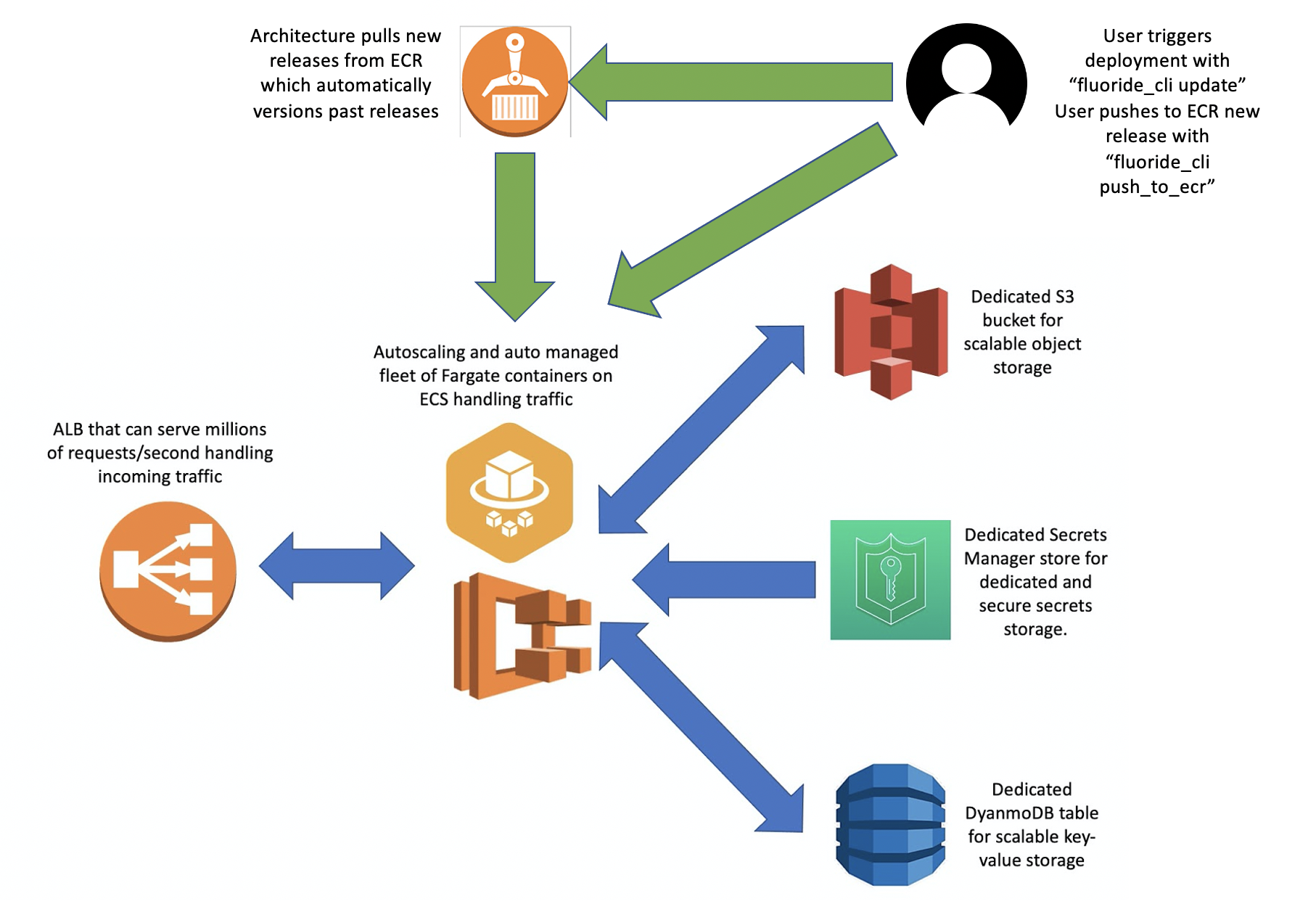
New deployments are triggered by pushing a new build to ECR. Then the user runs a Fluoride CLI command that tells the architecture to look for the latest release in its target ECR repo and use that release to trigger a new deployment. The architecture will wait for the new containers to spin up as healthy before routing traffic and draining connections to them and if they never spin up as healthy then the architecture automatically rolls back to the last stable release.
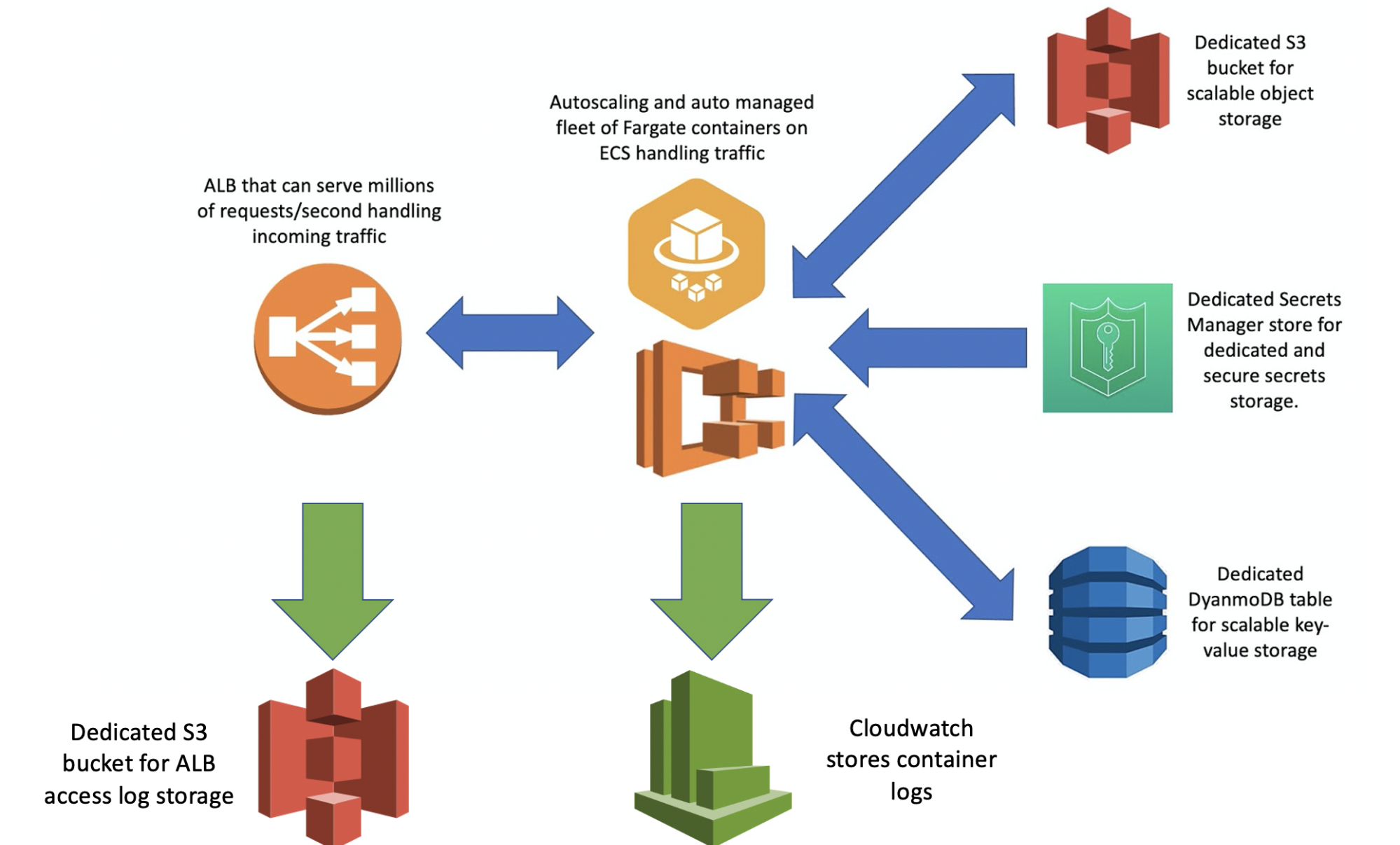
Every part of Fluoride is designed to be highly scalable; this includes logging. All access logs from the ALB are stored in an S3 bucket with Intelligent-Tiering turned on. Secrets storage is accomplished by making a Secrets Manager store accessible to all containers in our architecture, database storage is accomplished by making a DynamoDB accessible to all containers in our architecture, and object storage is accomplished by making an S3 bucket accessible to all containers in our architecture. The way that permissions are controlled allows for an architecture to totally own its connected DynamoDB, S3 bucket, and Secrets Manager store which allows developers to be totally confident in the state of all of these for each architecture and ameliorates fears that a rogue Fluoride microservice controlled by another team might make weird writes to your database that would compromise your service’s knowledge of state there. For all of your Fluoride architectures, there’s one way in and one way out for traffic (through the load balancer; which is logged which allows people developing for the architecture to have a sense of security regarding the state of their database, object storage, and secret storage). There are also options in the CloudFormation to toggle whether or not a DynamoDB, S3, or secrets managers are provisioned and whether or not a user provides their own custom names or has names automatically generated for them.
Another key component of this architecture was allowing users to specify a custom IAM policy ARN that they could specify in the CloudFormation used to set up Fluoride that would then be attached as part of an IAM role to their containers. This is important because it allows end users to extend the permissions of the architecture as they need these permissions extended. It’s foolish to think at the outset of creating an architecture that you’re going to be able to foresee all the ways it will be used so it can help for infrastructure you’re going to use widely and/or for an extended period of time to have features that will allow you to extend its functionality and easily integrate it with other systems down the road.
At Ginkgo, there’s a great utility in being quickly able to turn around certain systems for other teams and DevOps definitely has a desire to play ball in this regard. Not only is the process for setting up a new microservice with Fluoride relatively quick but what’s even better is that it’s easy enough to use that users can do it without a DevOps engineer. And since it’s been pre-approved through DevOps users can now stand up microservices to their heart’s content and no one from DevOps has to worry about these microservices contributing to support burden or compromising security down the road. Teams can very easily stand up many Fluoride stacks and wire them together with other Fluoride stacks or other infrastructure as they want and get really performant microservices that can help service and support their operations.
Utility
Developing and deploying digital infrastructure can be an annoying process if it’s not something you’re passionate about. I think it behooves people in the DevOps/SRE space to try to provide as much utility to users as possible while shielding them from the parts of our job that are our expertise. A lot of times by making all the options of different infrastructure available to our users we think we’ve done people a favor when in reality by offering so many choices we’ve actually made people’s lives a lot harder because they assume they need to think through all of them.
Especially for patterns that get repeated over and over again (i.e. a microservice, a batch workflow, certain aspects of networking, etc. etc.) it’s often good for DevOps/SREs (or teams in general who have concerns of a long term sort related to things like security and support burden) to weigh in heavily at the beginning of when architectures are conceived so that tools that satisfy all teams needs can be built.
The beauty of being a DevOps engineer is that the easier I make my own job the easier I make my coworkers jobs as well. If you can create infrastructure that serves a role and is easy enough for someone to use without a DevOps engineer you’ve provided a service to both parties involved. Myself because that’s one less person I need to help and the user of the infrastructure because they now have the ability to use new infrastructure to solve problems they may encounter on their own. Getting to the point where it’s possible to have a sort of self-service functionality for performant, secure infrastructure without having to understand too much about how the underlying operations work is not a bad goal to work towards.
Plea to Cloud Service Providers
I think we’ve gotten to the point where most cloud offerings are advanced enough that there are ways to directly provide useful outcomes without requiring engineers to worry too much about the arrangements of individual infrastructure components that allow this to happen. I think an error often made in approaching architecting in the cloud is that we often try to think of how we can replicate an onsite setup in the Cloud. There’s definitely advantages to be gained from just moving onsite setups to the Cloud especially from a maintenance perspective but I think there’s a lot of value to be gained in looking beyond that. Shepard can directly stand up a batch workflow and Fluoride can directly stand up a microservice without anyone really having to worry about what sort of on premises configuration they’d have to replicate in the cloud to get the same sort of functionality. So my plea to cloud service providers is this: “please start thinking more about providing the useful end state of cloud architecting to consumers rather than having them try to figure out how to get there themselves”.
I think the industry is sort of moving in this direction anyway. The way I see it AWS Lambda is kind of like this in that it’s a ready to go way to execute bursty workloads in which each discrete compute action requires a relatively small amount of compute. There is not a thought process when approaching using lambda where you say “how would I do this on premises?” and then try to replicate that in the cloud. It just does something very useful directly and cleanly integrates with all of AWS’s other services. I’d love if AWS or GCP or Azure or whoever provided a way to directly provision a microservice or directly provision a batch workflow or a supercomputing cluster without end users how to think about how to piece together other offerings to make these things happen.
I’ve been able to do some of this by tinkering with CloudFormation but there’s all sorts of things that AWS can do that I have no way of accomplishing (like adding things to boto or the aws CLI or other offerings that integrate with things I make in CloudFormation cleanly; i.e. while there are “aws s3 *” aws CLI commands there are no “aws fluoride *” aws CLI commands). I think most cloud service providers would be very good at designing a sort of “instant microservice” solution and I think the market (and myself) would love that. So, put simply, my ask to cloud service providers is to provide more services that provide the useful outcomes accomplished by arranging infrastructure components rather than providing more components for us to shuffle around and arrange ourselves.
(Feature photo by Superkitina on Unsplash)
