We conclude this year’s series on our Digital Technology Interns with the cool things that Ariel and Rohan did this summer!
Ariel Fuchs, Software Engineering Intern
Introduction
Hello! I am Ariel and I am a returning software engineer intern at Ginkgo Bioworks. This summer I was placed on the Digital Tech team called Samples Genomes and Strains (SGS). SGS oversees our Laboratory Information Management System (LIMS) which is where we store information regarding samples, their location and their biological content. Sample location management is crucial as it represents where the physical samples and containers live (so researchers know where to find them) and information involving their change history or lineage. I worked mainly on a project that oversaw the location management of containers, where containers are any physical entity that can hold information (i.e. test tube, well-plate, freezer etc).
Project
Problem
For my intern project, I was tasked with revamping our container import process. The import processes on LIMS allow our scientists to create or update information in bulk. Currently, users have to copy and paste a CSV file and click run in order to import their information. The component works great when there are no formatting or value errors to begin with. However, even one mistake with the formatting or the values provided will cause error messages to be displayed. Yet even the error messages present its own challenge.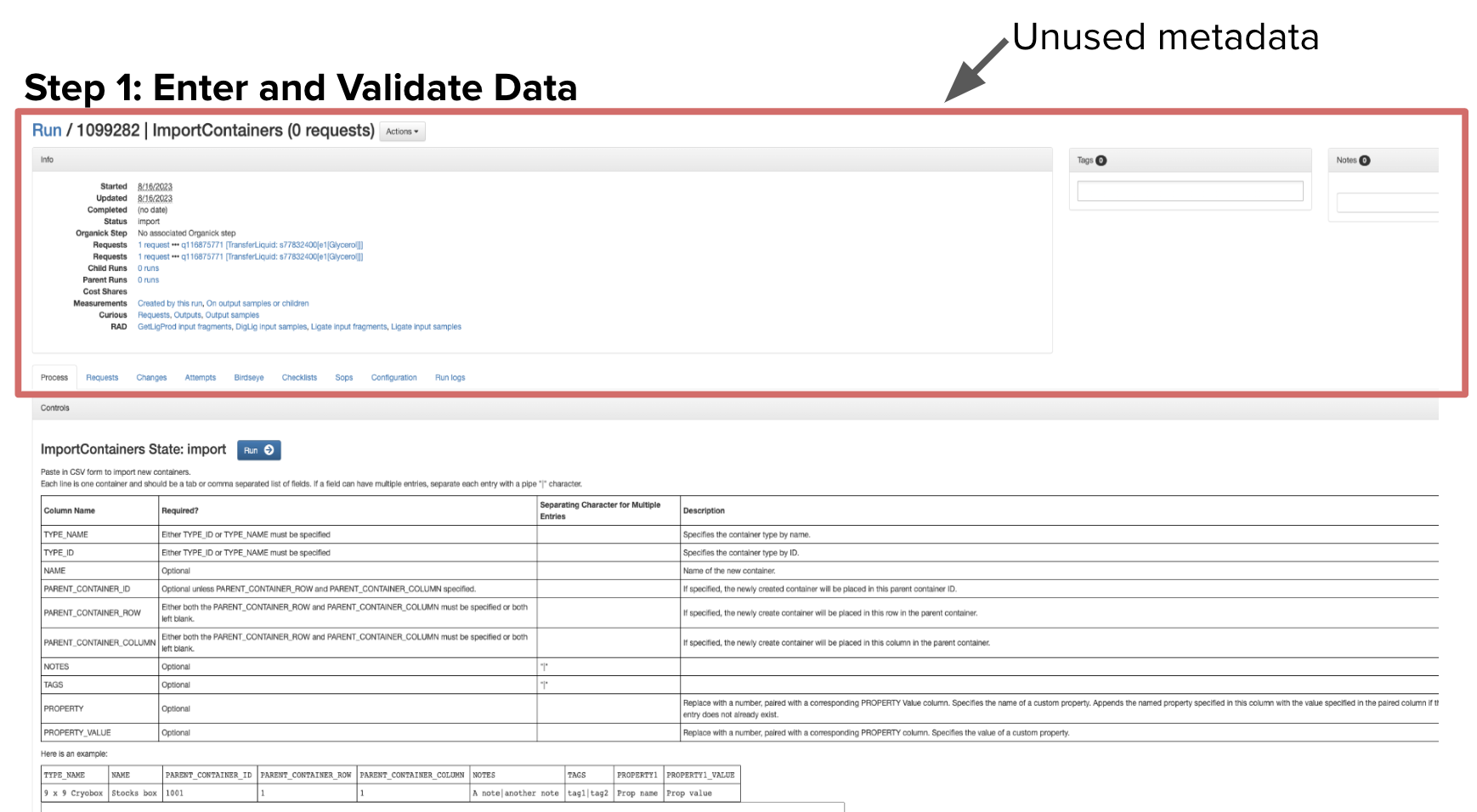
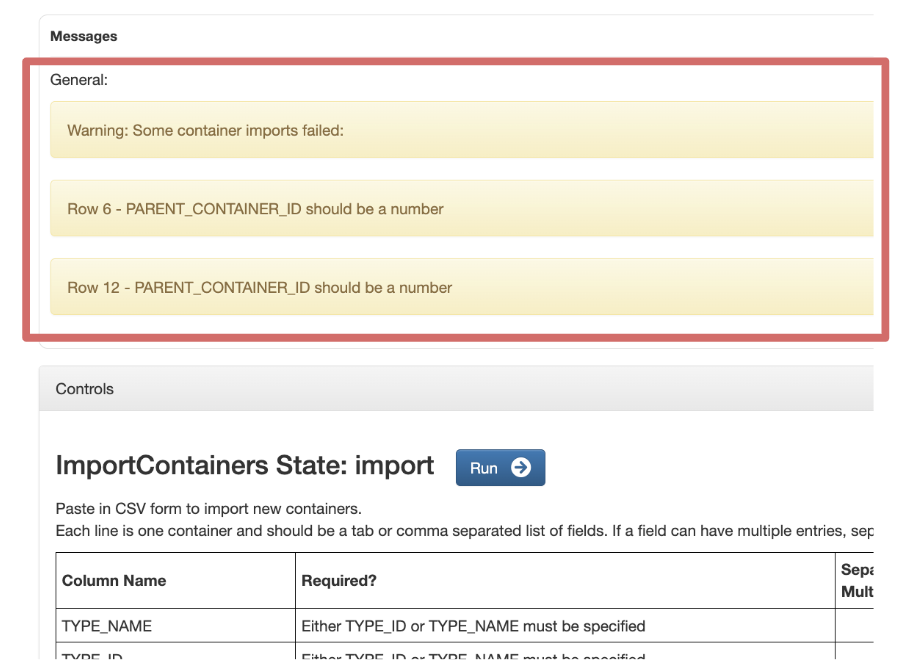
The first problem is that each error is displayed in its own text card. This takes up too much space if there are multiple errors. Second, the data users provide to import does not currently get reformatted to ease the process of editing. Users have to meticulously go through each row to find the right field to correct. Any change to the text input can result in new formatting errors that the user now has to correct without invoking any more. Lastly, the user has no method to check that their information is correct without submitting it in the process. So although the old way is functional, it doesn’t provide a clean user experience and can be frustrating to work with.
Solution
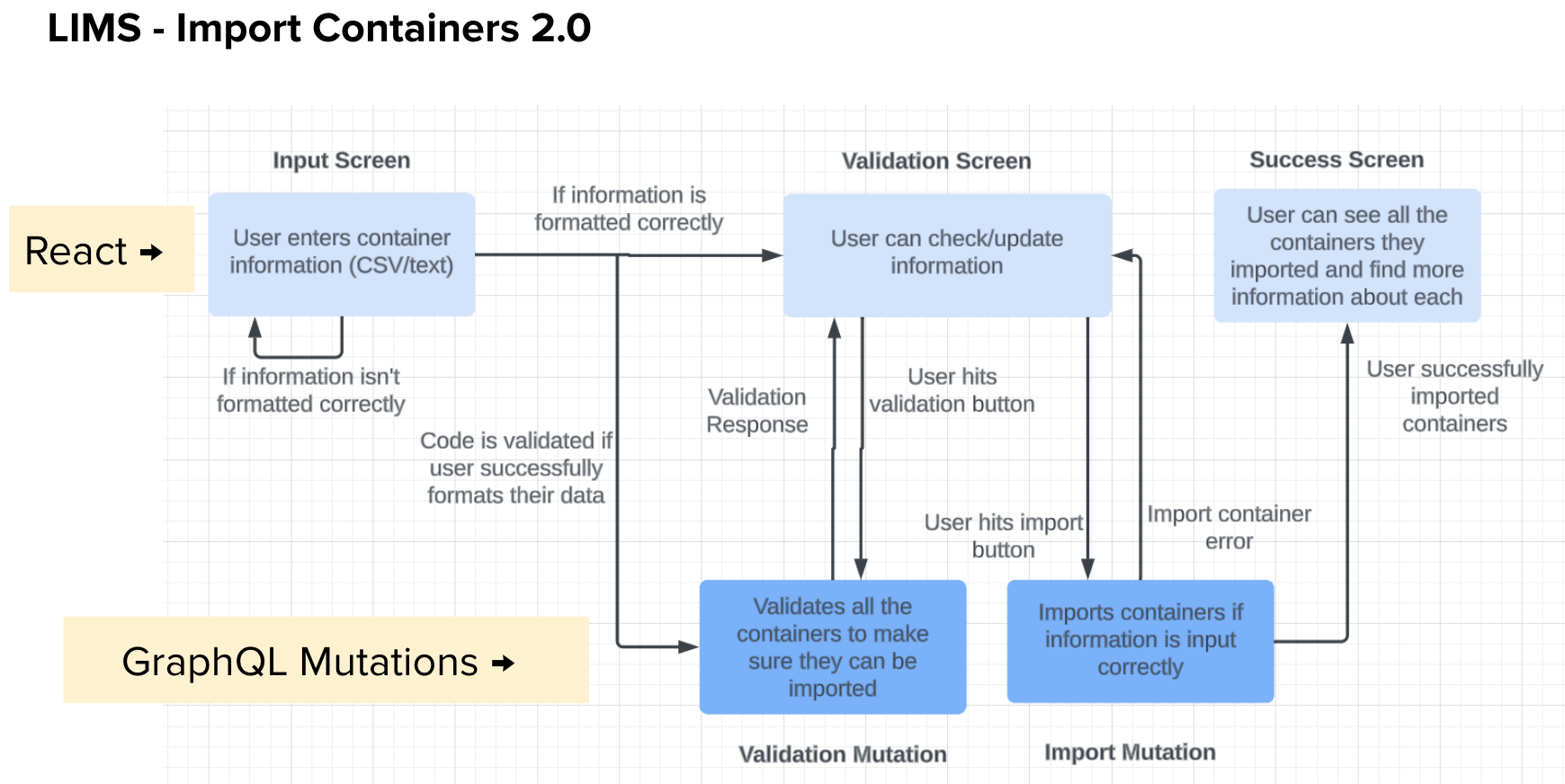
The biggest change to the Import Container Process was splitting up the steps to input, validate, and import the data.
Step 1: Entering Data. Users can now directly upload their CSV which can mitigate any formatting errors which arise from copy and pasting. If there are any formatting issues, these issues will be presented at the top of the page.
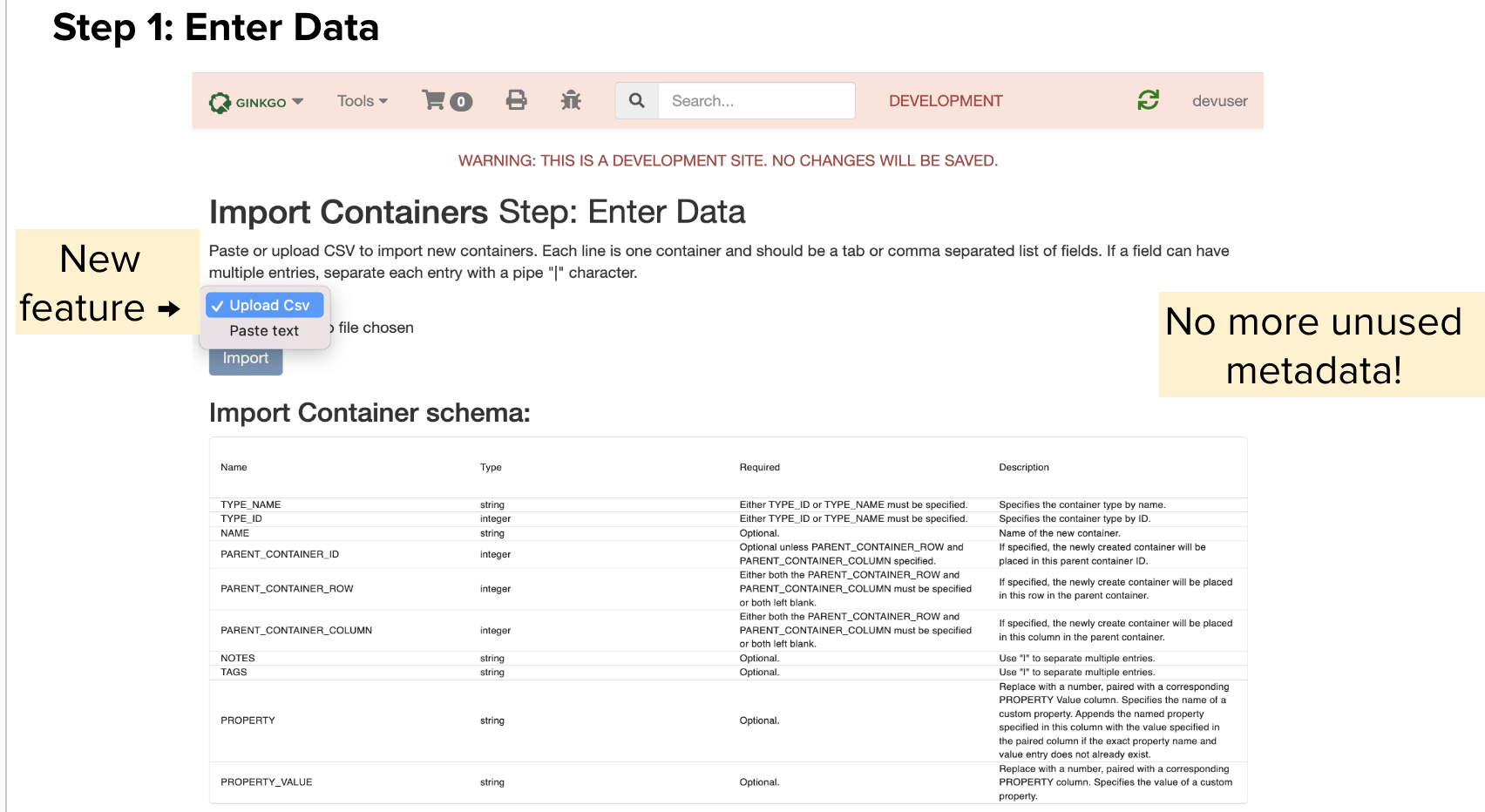
Step 2: Validate Data. Users will see their data reformatted into a table that they are able to edit or delete information. Users can validate their data and still make changes before they import the information. Any errors will prevent the user from importing their containers, but they can be easily resolved in this step. Error messages will appear both at the top of the page and at the table level so it is clear what needs to be corrected. Both the validation and import buttons rely on new GraphQL mutations that I created.
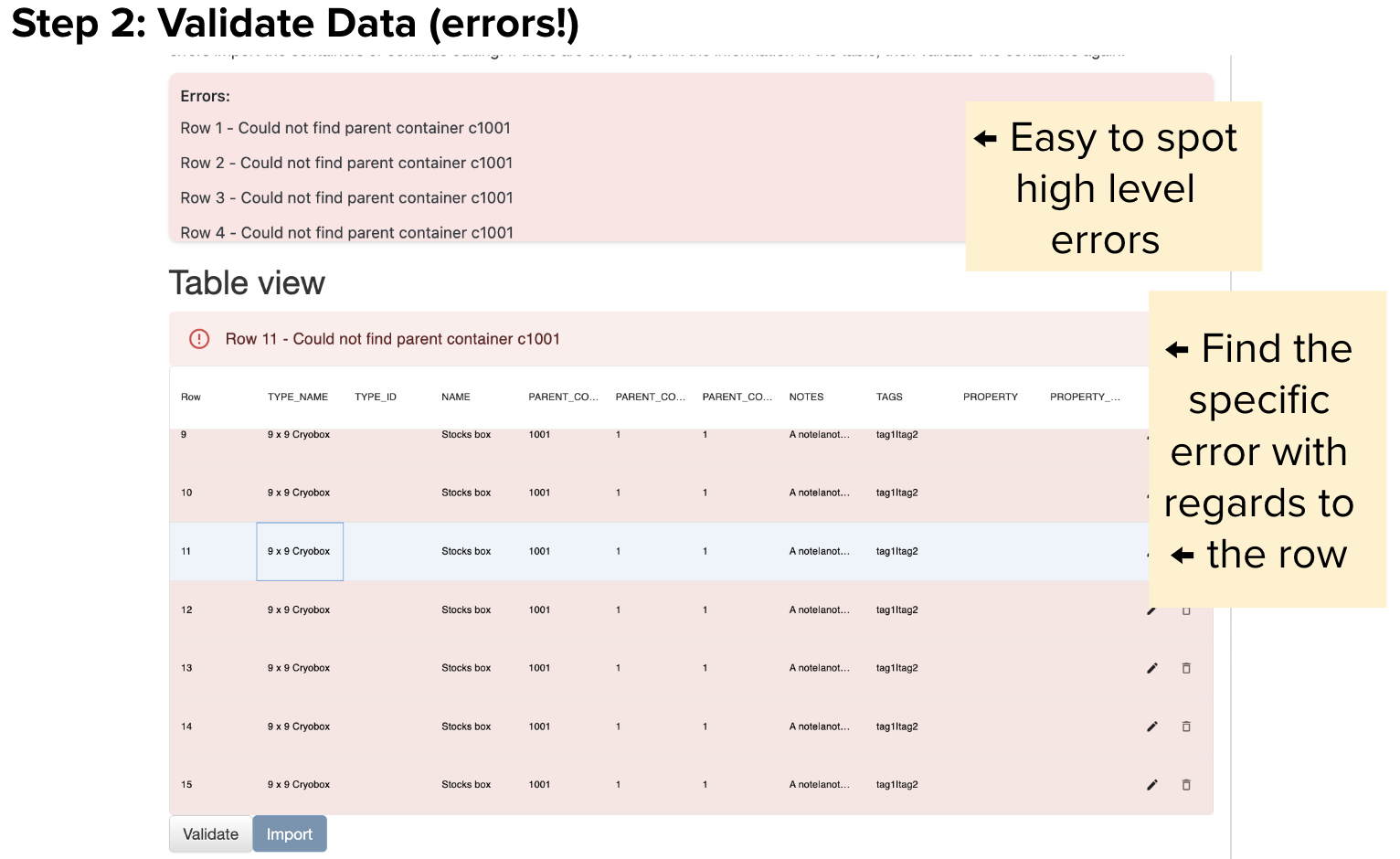
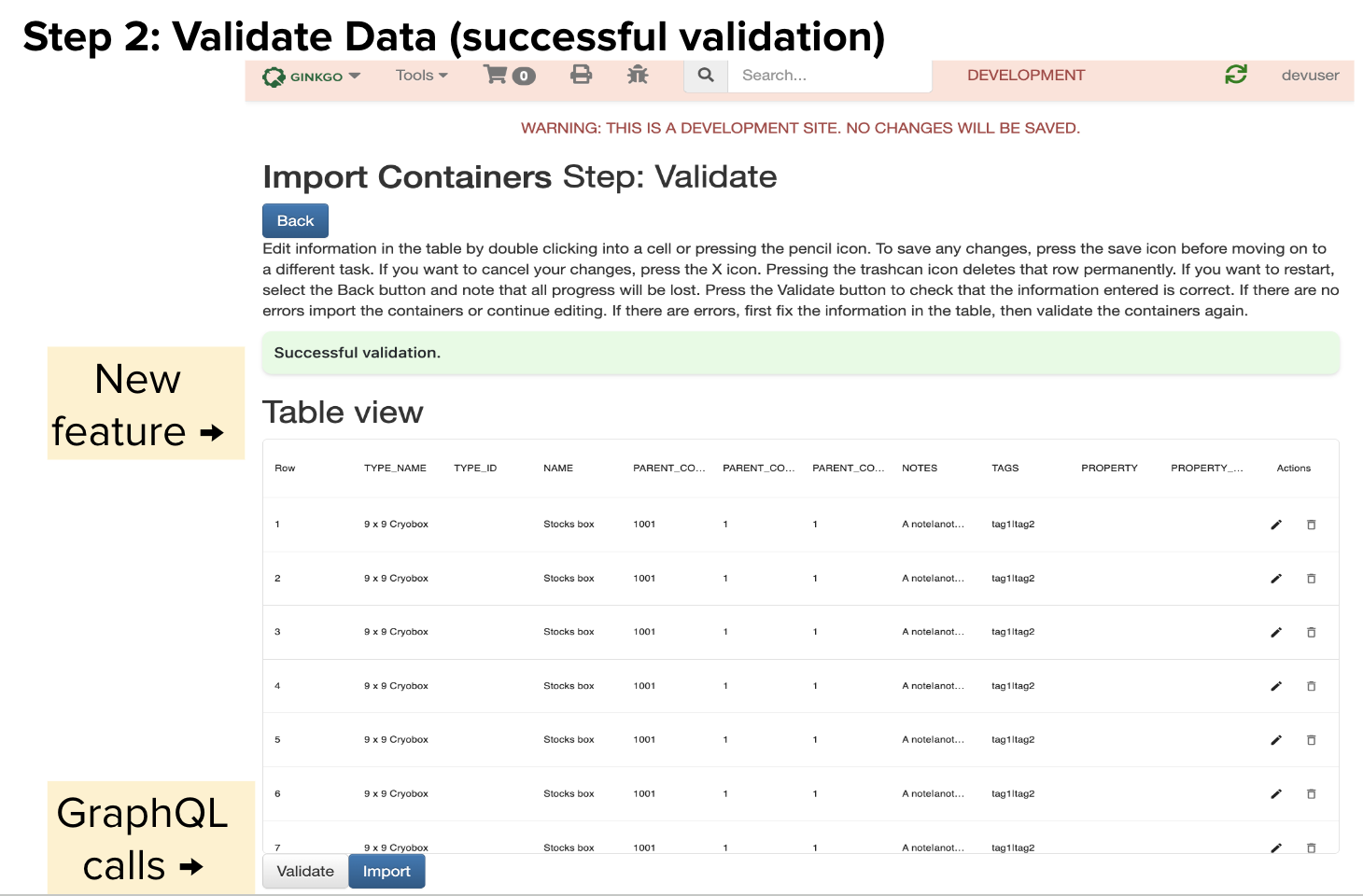
Step 3: When users have successfully imported their data, a list of the new ids created will be displayed. Users can then find more information about their containers by clicking the links on this success page or looking through the Container View dashboard elsewhere on LIMS.
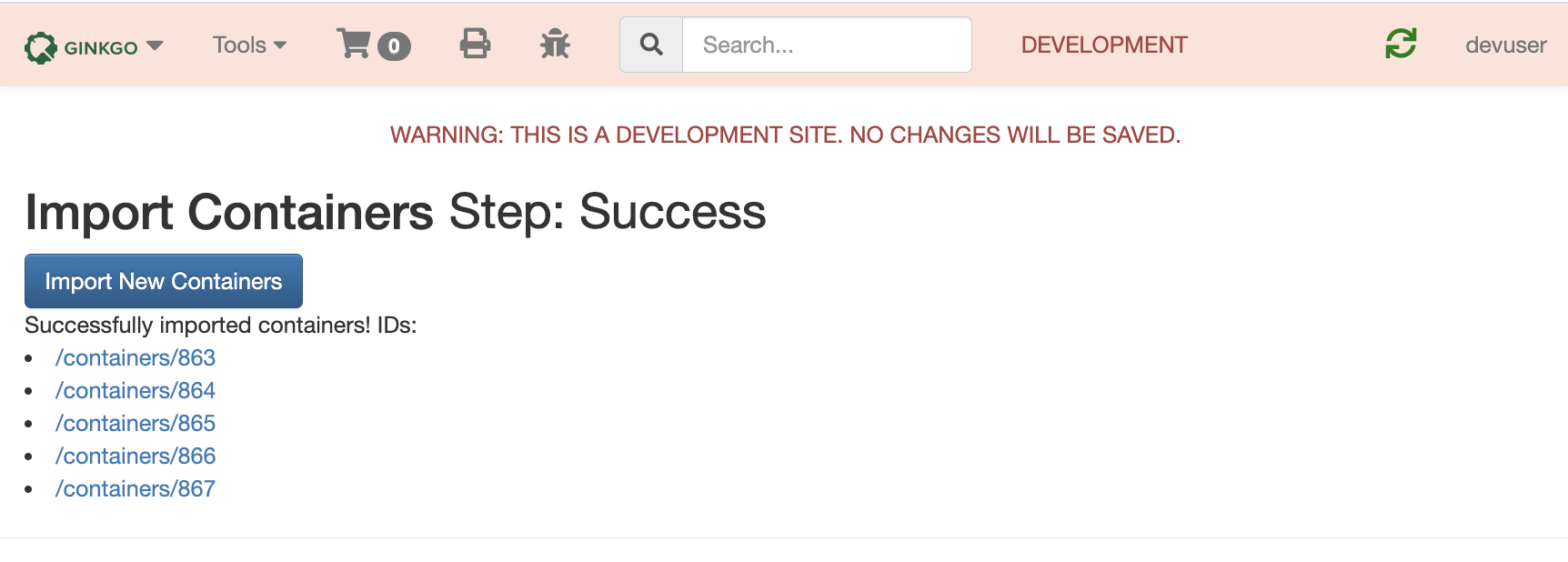
In addition to these changes, I created multiple tests to ensure that these mutations would catch any data entry errors. The new Import Container process has clear visuals, intuitive steps, and creates an overall streamlined experience for Ginkgo’s scientists. This will now be the template to improve the other import processes mentioned in the beginning of this post.
Conclusion
I gained many valuable skills this summer – learning how to create my own routes, GraphQL mutations, building different data structure views, and how to be resourceful when resolving problems. I have Yasmine Karni to thank for this successful summer as she is truly the best mentor. She created a strong learning environment, gave me freedom to explore my project, and frequently gave insightful feedback. In addition, I really appreciate the SGS team for being so supportive and encouraging. Lastly, a big shout out to the Early Talent team and the intern cohort. I loved the trivia nights, Early Talent Career sessions, and our BioDesign Presentation Competition! Working at Ginkgo Bioworks has given me two phenomenal summer experiences and insight into the software development world. I am thrilled to continue pursuing this career after my Master’s program at MIT in Computer Science and Brain and Cognitive Science. Thank you Ginkgo for helping me grow both professionally and personally, and I can’t wait to see how they change the world next!
Rohan Chhaya
Introduction
Hi! My name is Rohan and I’m pursuing my Bachelors in Bioengineering and my Masters in Data Science concurrently from the University of Pennsylvania. This past summer, I worked on the Design Center team, previously called the Terminators, to build out a new fullstack feature in Loom, Ginkgo’s platform for designing and ordering DNA. I appreciate everyone on the Design Center team for dealing with my endless barrage of questions as well as the users of this project. Big shoutout to my manager, Ashish Addepalli, and my mentor Luísa Galhardo, whom I bombarded with code review requests every single day.
Project
The goal of my project was to create a feature where users can mark certain DNA as a positive control, which is a benchmark that is known to produce an expected outcome in an experiment. Based on the number of DNA constructs being ordered, a certain number of replicates, or copies, of these controls would be added to the transaction and randomized on the plate. This end-to-end feature allows users to easily customize their experiments with controls while abstracting away the tediousness of remembering and replicating certain DNA controls.
Designing Control DNA Constructs
Users can already use a variety of tools, like the drag-and-drop workspace, to organize various pieces of DNA. These pieces are called “design units” and live in categories called buckets, like a promoter bucket for DNA that initiates gene transcription. In any given experiment, certain design units may be added to the design to be used as a positive control sequence. These design units can now easily be marked or unmarked as positive controls, complete with buttons and visual icons. Next, users create constructs by assembling together in a combinatorial manner (for example, 2 buckets with 2 design units each → 4 constructs). Any construct that has a design unit that was marked as a positive control automatically inherits this positive control designation.
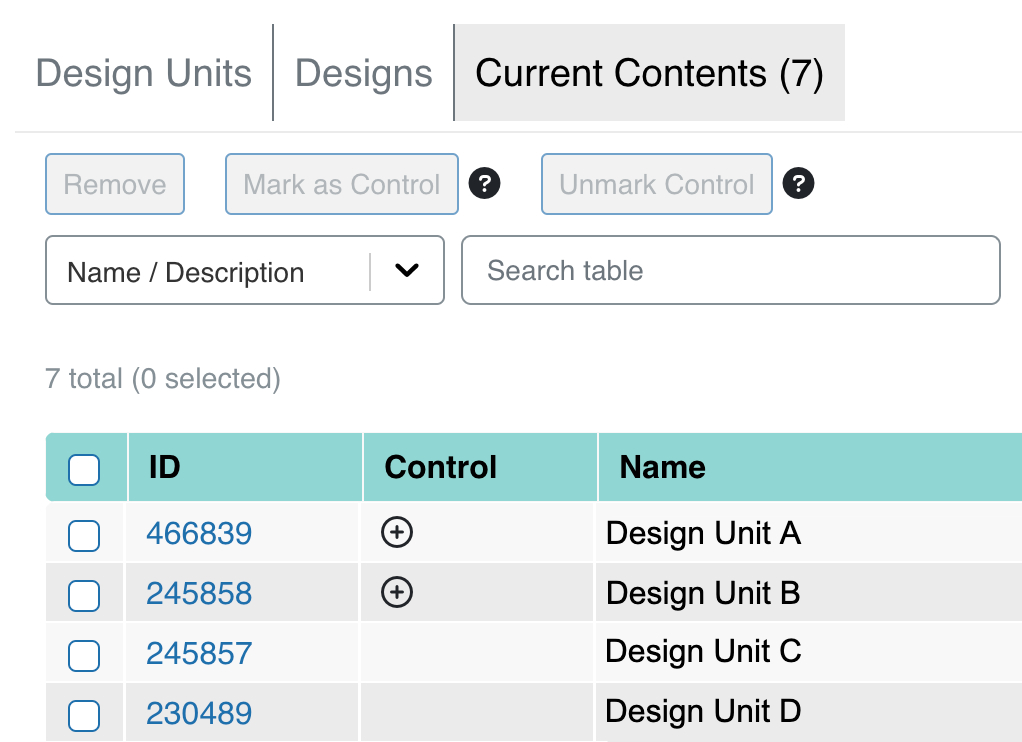
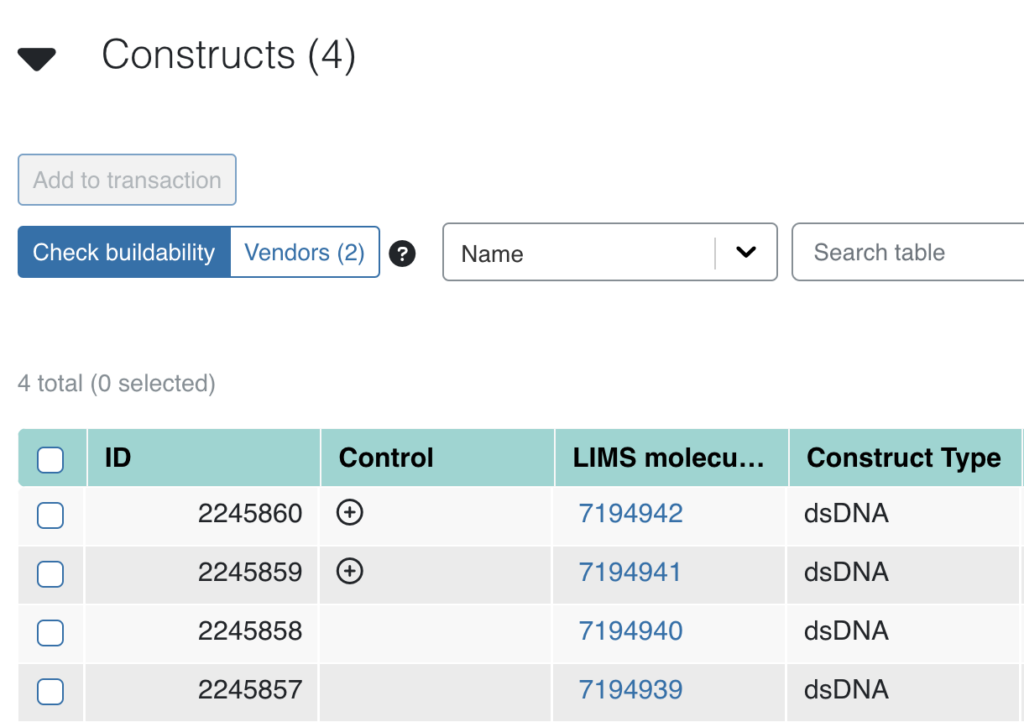
The design units (left) can be marked or unmarked as control, and the constructs created from them (right) inherit the designation. For example, Design Unit A is part of the top construct.
Adding to Transaction and Calculating Replicates
When the design is ready to order, users can create a transaction that has all the constructs in the design. On the transaction page, the control constructs float to the top for easy visualization in large transaction sizes. Based on data collected from the High Throughput Sequencing team, we can calculate how many replicates to add to the transaction. I designed an informative card explaining the math and links to the relevant design/design unit used to define the controls. When the user is ready to place the order, there is a pop-up confirming the new transaction size.
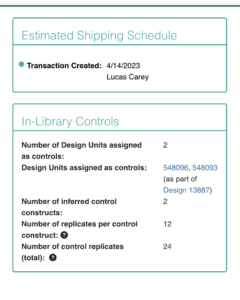
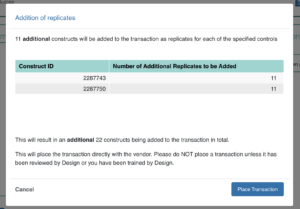
Ordering and Randomizing
To execute an order, we use another internally developed software called Orderly, which automates all DNA ordering with some of our vendors. Within Orderly, we can check to see if the order has positive controls and if so, we randomize the molecule ordering on the plate before placing the order with our vendors. This helps improve the blinding of the experiment, since the locations of the positive controls should be unknown to the biologist working with the plate.
My Ginkgo Experience
I had a blast this summer at Ginkgo! As someone with a background in biology and computer science, it was really cool to mix those two worlds together and work on a meaningful project that people were looking forward to using and is now in production.
I was able to improve my technical skills by working in languages and frameworks that were brand-new to me. Thanks to some of the intern events put together by the Early Talent team, I even had the opportunity to chat with upper-level executives about Ginkgo’s business strategies and the broader biotechnology industry.
Outside of the office, I had so much fun exploring Boston with my fellow interns, from kayaking on the Charles, to restaurant-hopping in Chinatown, to exploring Cape Cod. I’m very grateful to everyone who made my summer one to remember!
Conclusion
It has a been a great summer and we wish Digital Tech Team Interns well. Thank you for your impressive contributions and we hope that you have a great year!
(Feature photo by Saiph Muhammad on Unsplash)


