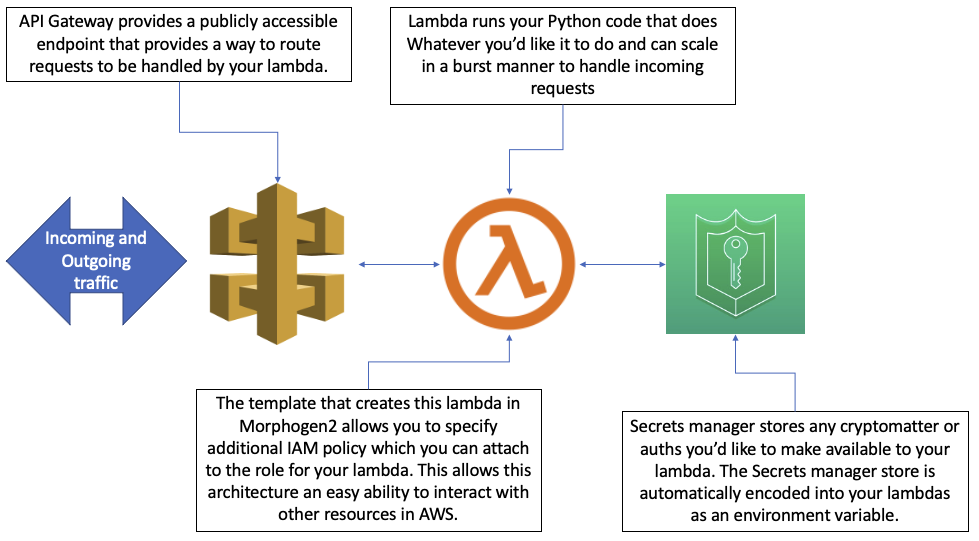
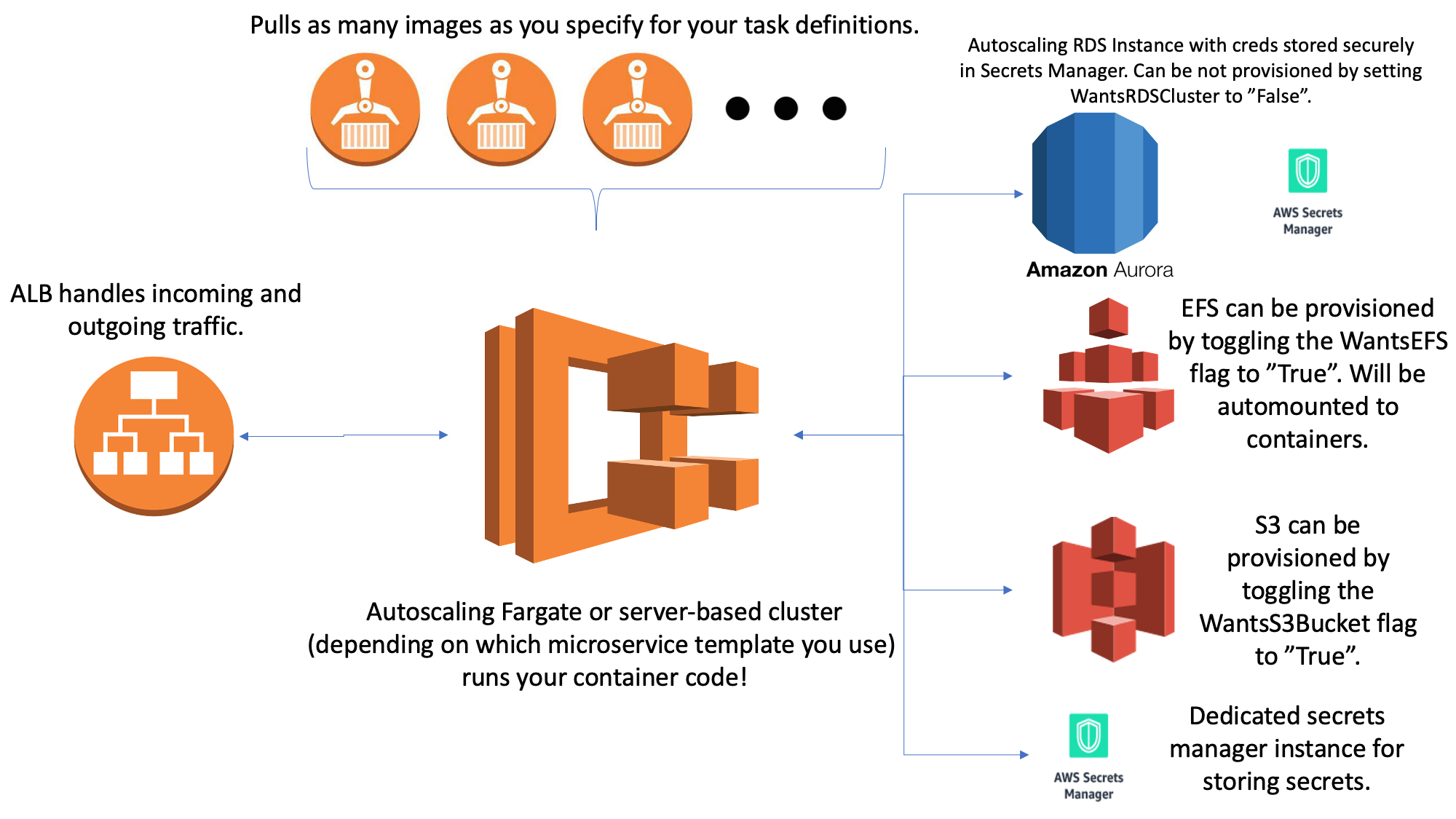
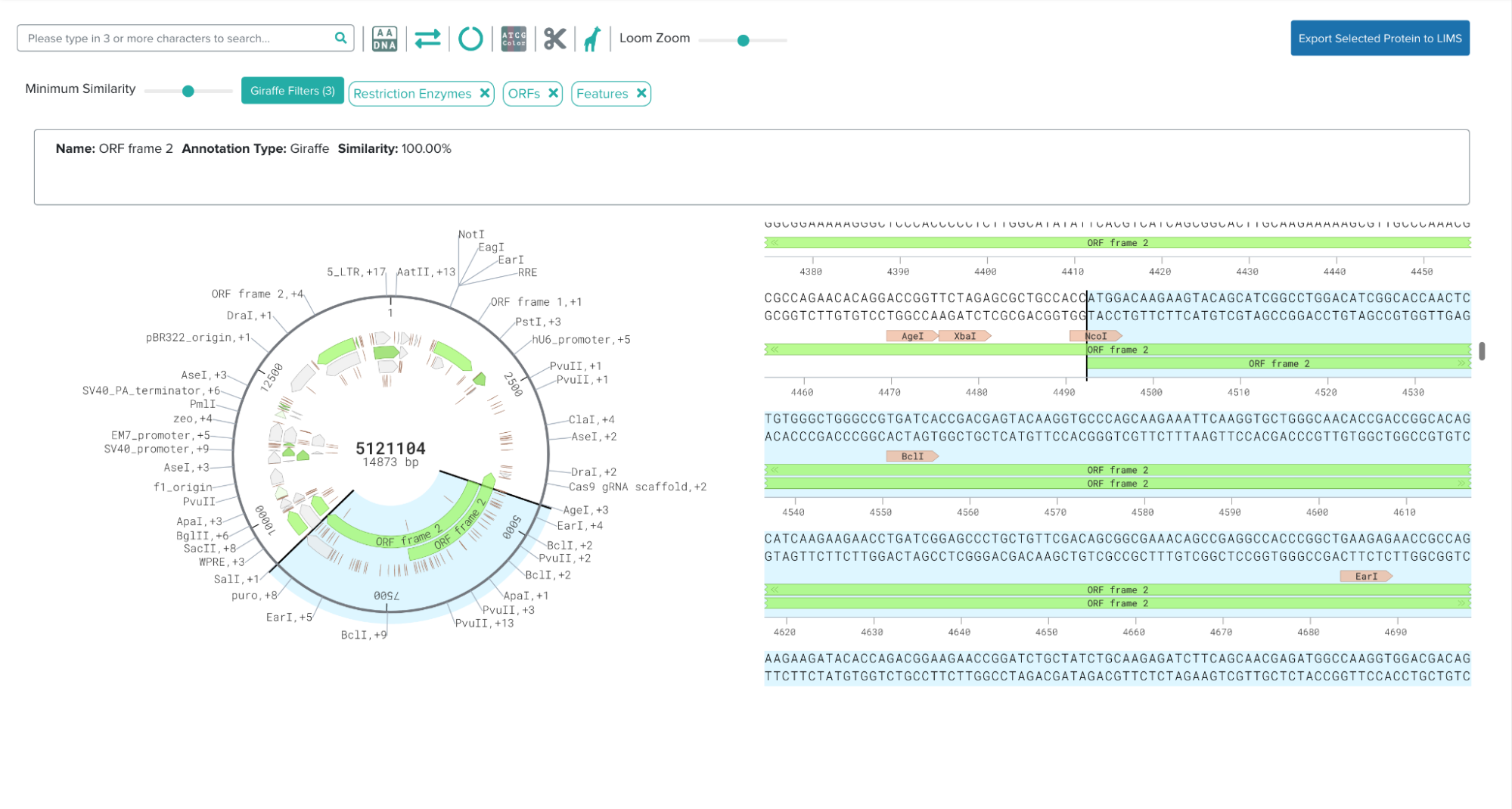
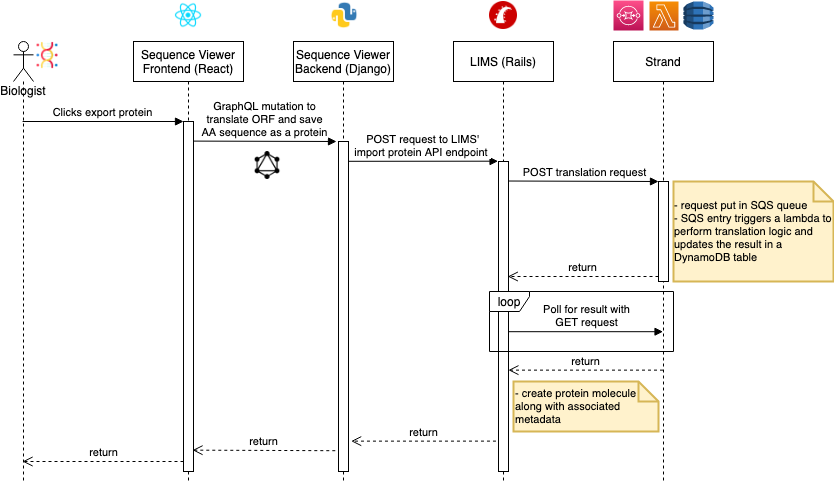
TLDR;
Cross-functional teams can be hard to manage in terms of traditional Group based access control. Yellowstone is our effort to create meaningful role based authentication that scales and services the needs of Ginkgo.
Background
Ginkgo, like most companies with a startup-like mentality, has a culture of wearing many hats. It is not too uncommon to see some of our wet lab people diving into the complexities of our AWS infrastructure or to be limited to just one project scope. In our infrastructure we tend to segregate a lot of different projects and services into their own AWS subaccount within our AWS organization. This on occasion makes it rather tricky to manage group memberships to each subaccount on an as needed basis. Our working solution thus far follows the pattern of each user as the sole member of their own access group in AWS with a policy document describing the explicit roles they can assume into on a subaccount by subaccount basis.
{
"Version": "2012-10-17",
"Statement": [
{
"Resource": [
"arn:aws:iam::123456789012:role/TestRole",
"arn:aws:iam::123456789012:role/ElevatedRole",
"arn:aws:iam::123456789012:role/AdvancedRole",
"arn:aws:iam::123456789013:role/ElevatedRole",
"arn:aws:iam::123456789013:role/AdvancedRole",
"arn:aws:iam::123456789013:role/BasicRole",
"arn:aws:iam::123456789014:role/BasicRole",
"arn:aws:iam::123456789014:role/ElevatedRole",
"arn:aws:iam::123456789015:role/ElevatedRole",
"arn:aws:iam::123456789015:role/BasicRole",
],
"Effect": "Allow",
"Condition": {
"BoolIfExists": {
"aws:MultiFactorAuthPresent": "true"
}
},
"Action": "sts:AssumeRole"
},
{
"Resource": "*",
"Effect": "Allow",
"Condition": {
"BoolIfExists": {
"aws:MultiFactorAuthPresent": "true"
}
},
"Action": "sts:DecodeAuthorizationMessage"
}
]
}
This is great if policy documents in AWS aren’t fixed size objects and users do not need a ton of subaccounts but quickly running through the worst case scenario shows that this is not a scalable solution. Generally speaking this leaves us with ~150 possible unique subaccount permissions. This restriction on IAM limits our ability to scale with the sheer number of projects and also make it difficult to quickly audit our users by glancing at their permission set.
Enter Yellowstone
Named after the potentially calamitous volcanic structure that threatens the entirety of the western continental United States, Yellowstone is the framework that the devops team at Ginkgo designed to combat our permissions scaling issue. It consists of several components: a dynamo DB table for maintaining global definitions for team to role pairings, a rectification script to manage to keep our subaccounts in alignment with the dynamo db table, a group provisioning script to generate new groups within Yellowstone, a user management scripts to add users to groups, and an audit script to present to auditors.
Components
The pieces of our multi-subaccount IAM solution are comprised of a Dynamo DB to act as a single source of truth, a number of scripts that read from and manipulate the state of the database, and a Service Control Policy (SCP) to prevent our user base from manually “fixing” our Yellowstone permissions. Our Dynamo DB table is a fairly flat table with the following schema. For every permission we grant we create a record with the team name, readable name of the subaccount, allowable IAM role for the target subaccount, and active permissive state. We include this active permissive state because internally we never want to reduce the amount of permissions in our table for historical audit reasons.
Our first automation component is our account provisioning script, this script is run whenever we want to add or manipulate a particular subaccount’s permissions within the dynamo DB table. This is pretty simple: just a read of the database table to see if a record with the subaccount/team name exists and an update that record with our new information. If the subaccount/team pair doesn’t exist we create it in the database.
usage: account_provision.py [-h] -m MODE -a ACCT -r ROLE -t TEAM optional arguments: -h, --help show this help message and exit -m MODE, --mode MODE Mode to execute either add or delete -a ACCT, --acct ACCT Specify desired human-readable sub-account name -r ROLE, --role ROLE Specify desired role -t TEAM, --team TEAM Specify desired team $ python account_provision.py -m add -a accountfoo -r role1 -t IT
Note that because we want our Yellowstone database table to be an auditable source of truth, the delete flag won’t remove the permission relationship from the table; it will just set the permissive state from true to false.
The next (arguably the most important script) is the rectification script, this script allows us to refresh the state of our cross account AWS permissions by fetching all of the records in our DynamoDB table and updating the tags in the individual subaccount roles to match the state of the database. Again to preserve audibility this script does not remove roles if the dynamo record is false; instead it will change the tag to false to match the state of the table.

Because we want to prevent our users (or rogue devops engineers) from creating new tags on these subaccounts, this script also toggles the SCP we create to block tag manipulation on allowing us to circumvent the SCP.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "BlockYellowstone",
"Effect": "Deny",
"Action": [
"iam:TagRole"
],
"Resource": [
"*"
],
"Condition": {
"ForAnyValue:StringLike": {
"aws:TagKeys": [
"ACCESS-*"
]
}
}
}
]
}
The next component is the user management script which allows us to do two things: audit a particular user and manipulate the relationship between a user and a Yellowstone group. This allows users to allow them access to all IAM resources tagged with their Access-{TeamName}: True tags. This looks fairly similar to the legacy style but instead of explicitly calling out the STS IAM assume role permissions we instead allow users to assume to any STS IAM Role with the appropriate tag set.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": "*",
"Condition": {
"StringEquals": {
"iam:ResourceTag/ACCESS-IT": "True"
}
}
}
]
}
Finally our audit script is pretty straightforward, We dump the contents of the audit script as well as the IAM policy documents of all of our users. This is a major improvement for both us (the administrative team) as well as the auditing teams because all of the information is easily readable without the need to cross-reference the 12 digit account number with its human readable name.
Places to Improve
The biggest performance issue with this new authentication system has to do with the way we prevent individual contributors from jail-breaking our system. We accomplish this through an AWS organization level service control policy (SCP). This SCP blocks users from manipulating the access tags on each of the subaccounts. One of the greatest points of friction in AWS organizations is how difficult the API is with representing the attachment state of a document. I ultimately had to settle on using a hardcoded wait for the SCP to detach the policy.
Acknowledgements
I’d like to thank all of my team members, in particular the principal engineer who architected this framework and my manager for letting me learn AWS through this project. Prior to Ginkgo, I didn’t have a lot of experience with developing automation with boto3 and this project was a really nice springboard into automating AWS resources.
(Feature photo by Nicolasintravel on Unsplash)